Using the Virtual Ecosystem#
This page provides a brief demonstration of the Virtual Ecosystem model in operation. Once you have installed the Virtual Ecosystem, you should be able to replicate this example on your own computer using the commands below.
Example model data#
The demonstration requires an installation of the example data provided with the Virtual Ecosystem package. If you have previously attempted to run this example then the simulation will refuse to overwrite existing output files. You can either:
delete the existing example data folder and reinstall it,
create a fresh installation using a different location, or
create and use a new output directory with the existing example data folder.
It is worth re-reading the example data page to get an overview of the directory structure and the configuration and data files.
The ve_run command#
You’ve already used this command to install the example data but most of the options to
the ve_run command are used to run the simulation. The --help option can be used to
show the various arguments that can be used to set how a model runs:
ve_run --help
ve_run --help
ve_run --help
usage: ve_run [-h] [--version] [--install-example INSTALL_EXAMPLE]
[-o OUTPATH] [-c CLI_CONFIG] [--validate-config-only]
[-p CLI_PATHS] [--logfile LOGFILE] [-q]
[cfg_paths ...]
Configure and run a Virtual Ecosystem simulation.
This program sets up and runs a Virtual Ecosystem simulation. The program expects
to be provided with paths to TOML formatted configuration files for the simulation.
The configuration is modular: a directory path can be used to add all TOML
configuration files in the directory, or individual file paths can be used to select
specific combinations of configuration files. These are combined and validated and
then used to initialise and run the model.
As an alternative to providing configuration paths, the `--install-example` option
allows users to provide a location where a simple example set of datasets and
configuration files provided with the Virtual Ecosystem package can be installed.
This option will create a `ve_example` directory in the location, and users can
examine the input files and run the simulation from that directory:
`ve_run /provided/install/path/ve_example`
The output directory for simulation results is typically set in the configuration
files, but can be overwritten using the `--outpath` option. A log file path can be
provided for logging output. If this is not provided then the log will be written to
the console, but the logging is typically verbose and it is usually better to
redirect the log to a file.
When logging is redirected to a file, a short progress report is written to stdout.
By default, the command reports: the start and end of the simulation and log
location; the completion of simulation stages; and a progress bar over the time
steps of the model. The `--quiet` command can be used to incrementally mute this
output: `-q` will remove the progress bar, `-qq` just prints the start and stop and
`-qqq` mutes the report entirely.
The `--config` option can be used to override configuration settings provided in the
file or to add additional settings. This is typically used to run a set of parallel
simulations that vary configuration settings of interest around a central
configuration setup, without the need to write a specific configuration file for
each permutation.
The `--data-path` option can be used to dynamically set the location of data paths
in the configuration. A file path in the config can be set as a path marker, which
must be a string starting with a "$", for example "$CLIMATE_DATA". This option can
then be used to substitute different files into that marker for different runs:
`--data-path CLIMATE_DATA=/path/to/file.nc`.
The `--validate-config-only` flag can be used to only run the configuration
validation part of the model setup and the exit before running any models.
The resolved complete configuration will then be written to a single consolidated
config file in the output path with a default name of
`ve_full_model_configuration.toml`. This can be disabled by setting the
`core.data_output_options.save_merged_config` option to false. Note that the merged
configuration automatically converts all file paths within the merged configurations
to absolute file paths - this ties the merged configuration to the file system where
the run is executed.
positional arguments:
cfg_paths Paths to config files
options:
-h, --help show this help message and exit
--version show program's version number and exit
--install-example INSTALL_EXAMPLE
Install the Virtual Ecosystem example data to the
given location
-o, --outpath OUTPATH
Path for output files
-c, --config CLI_CONFIG
Override configuration settings
--validate-config-only
Exit after validating configuration
-p, --data-path CLI_PATHS
Set data paths used for input data
--logfile LOGFILE A file path to use for logging a Virtual Ecosystem
simulation
-q, --quiet Quieten the default progress reporting
Running the example model#
The code below runs a simulation using the example data. The command uses the command line options to set three things:
It points to the files in
configdirectory that should be used configure the model. N.B. this directory contains configuration for all possible model combinations so providing just theconfigdirectory as a path will result in an invalid configuration.It sets the output directory to be used by the simulation to
out. You could create a new output directory (e.g.out_test_2) and change this to run a new simulation using the existing data.It redirects the model logging to a file in the output directory, rather than printing it all to screen.
When the detailed logging is redirected to a file, the command generates a short
progress report to show the model running. This can be made shorter or completely muted
by using the -q argument: repeat the argument to remove more details (e.g. -qq or
-qqq).
Warning
If the path provided for the log points to a file that already exists the detailed logging is added to the end of the file rather than creating a new file. We would recommend creating a new logfile for each simulation as reusing files in this way can create confusion.
In the example code below, the ve_example folder has been previously installed under the directory /tmp/
ve_run /tmp/ve_example/config/data_config.toml \
/tmp/ve_example/config/abiotic_simple_config.toml \
/tmp/ve_example/config/animal_config.toml \
/tmp/ve_example/config/hydrology_config.toml \
/tmp/ve_example/config/litter_config.toml \
/tmp/ve_example/config/plant_config.toml \
/tmp/ve_example/config/soil_config.toml \
--out /tmp/ve_example/out \
--logfile /tmp/ve_example/out/logfile.log
ve_run C:\tmp\ve_example\config\data_config.toml ^
C:\tmp\ve_example\config\abiotic_simple_config.toml ^
C:\tmp\ve_example\config\animal_config.toml ^
C:\tmp\ve_example\config\hydrology_config.toml ^
C:\tmp\ve_example\config\litter_config.toml ^
C:\tmp\ve_example\config\plant_config.toml ^
C:\tmp\ve_example\config\soil_config.toml ^
--out C:\tmp\ve_example\out ^
--logfile C:\tmp\ve_example\logfile.log
ve_run C:\tmp\ve_example\config\data_config.toml `
C:\tmp\ve_example\config\abiotic_simple_config.toml `
C:\tmp\ve_example\config\animal_config.toml `
C:\tmp\ve_example\config\hydrology_config.toml `
C:\tmp\ve_example\config\litter_config.toml `
C:\tmp\ve_example\config\plant_config.toml `
C:\tmp\ve_example\config\soil_config.toml `
--out C:\tmp\ve_example\out `
--logfile C:\tmp\ve_example\logfile.log
* Starting Virtual Ecosystem simulation using v0.2.0.
* Logging to: ve_example/out/logfile.log
* Loading configuration
* Configuration validated
* Saved compiled configuration: ve_example/out/compiled_configuration.toml
* Built core model components
* Initial data loaded
* Models initialised: abiotic_simple, animal, hydrology, litter, plants, soil
* Initialisation data export complete.
* Starting simulation
100%|██████████████████████████████████████████| 24/24 [01:05<00:00, 2.73s/it]
* Simulation completed
Virtual Ecosystem run complete.
The log file is very long and shows the step by step process of running the model - it is primarily used for diagnosing problems with the model. You can view a sample of the contents in the dropdown below:
Partial log output
[INFO] - main - ve_run(286) - Using Virtual Ecosystem v0.2.0.
[INFO] - config_builder - _collect_config_paths(427) - Config paths resolve to 7 files
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/data_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/abiotic_simple_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/animal_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/hydrology_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/litter_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/plant_config.toml
[INFO] - config_builder - _load_config_toml(450) - Config TOML loaded from ve_example/config/soil_config.toml
[INFO] - config_builder - _compile_data(374) - Configuration data compiled.
[INFO] - registry - _register_module(163) - Registering module: virtual_ecosystem.core
[INFO] - registry - _register_module(176) - Configuration class registered for virtual_ecosystem.core
[INFO] - registry - _register_module(163) - Registering module: virtual_ecosystem.models.abiotic_simple
[INFO] - registry - _get_model(237) - Registering model class for virtual_ecosystem.models.abiotic_simple: AbioticSimpleModel
[INFO] - registry - _register_module(176) - Configuration class registered for virtual_ecosystem.models.abiotic_simple
[INFO] - registry - _register_module(163) - Registering module: virtual_ecosystem.models.animal
[INFO] - registry - _get_model(237) - Registering model class for virtual_ecosystem.models.animal: AnimalModel
[INFO] - registry - _register_module(176) - Configuration class registered for virtual_ecosystem.models.animal
[INFO] - registry - _register_module(163) - Registering module: virtual_ecosystem.models.hydrology
[INFO] - registry - _get_model(237) - Registering model class for virtual_ecosystem.models.hydrology: HydrologyModel
--- many lines omitted ---
[INFO] - data - __setitem__(237) - Replacing data array for 'plant_pft_propagules'
[INFO] - plants_model - update_canopy_layers(864) - Updated canopy data on 1
[INFO] - data - __setitem__(237) - Replacing data array for 'shortwave_absorption'
[INFO] - data - __setitem__(237) - Replacing data array for 'plant_ammonium_uptake'
[INFO] - data - __setitem__(237) - Replacing data array for 'plant_nitrate_uptake'
[INFO] - data - __setitem__(237) - Replacing data array for 'plant_phosphorus_uptake'
[INFO] - data - __setitem__(237) - Replacing data array for 'stem_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'senesced_leaf_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'plant_reproductive_tissue_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'root_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_vegetation_cnp'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_seedbank_cnp'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_vegetation_litter_cnp'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_seedbank_litter_cnp'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_vegetation_litter_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_seedbank_litter_lignin'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_ammonium_uptake'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_nitrate_uptake'
[INFO] - data - __setitem__(237) - Replacing data array for 'subcanopy_phosphorus_uptake'
[INFO] - base_model - update(439) - Updating animal model
Looking at the results#
The Virtual Ecosystem writes data out to a Zarr data store. This is a relatively new open-source format that is designed for use with large multi-dimensional data. It is used in the Virtual Ecosystem because the format supports appending data at each time step, making it easy to build up a single integrated dataset during the model run. This also means that if a model crashes, then the output variables will be structured in a single datastore as time series up until the crash point.
The default output filename is model_data.zarr but this can be changed in the output
configuration. Although the file suffix makes that
look like a single file, the Zarr format is actually a directory structure, containing
variables or groups of variables. The Virtual Ecosystem outputs data into one of three
groups, depending on when the values are calculated.
The
inputsgroup: variables that loaded at the start of the simulation from the model data configuration. Obviously, these data are in your input files, but it can be convenient to have them packaged within a single data source alongside the model outputs.The
initgroup: variables that are calculated during the initialisation process of science models are written to this group. These values capture the state of the model before the model starts to iterate through time. You might not plot them as part of a time series but they can be very useful for understanding how your input data is used to set the model running.The
outputsgroup: variables that are calculated by the science models at each time step. The data are added to the data store at the end of each time step.
For more details on the variables used in the Virtual Ecosystem and to see which variables are part of the inputs, initialisation and outputs, see the variables table.
Note
The configuration for the example model exports all of the variables used in the model. If you only require some of the variables for your analayses, you can alter the output configuration to export a subset of the variables.
The sections below go into more detail on each data group, the code below uses the
xarray and matplotlib Python packages to load and visualise output data. You may
need to install these to replicate these outputs on your own computer.
import matplotlib.pyplot as plt
import numpy as np
import xarray
Input data#
The inputs group contains variables that users are required to provide to run the model.
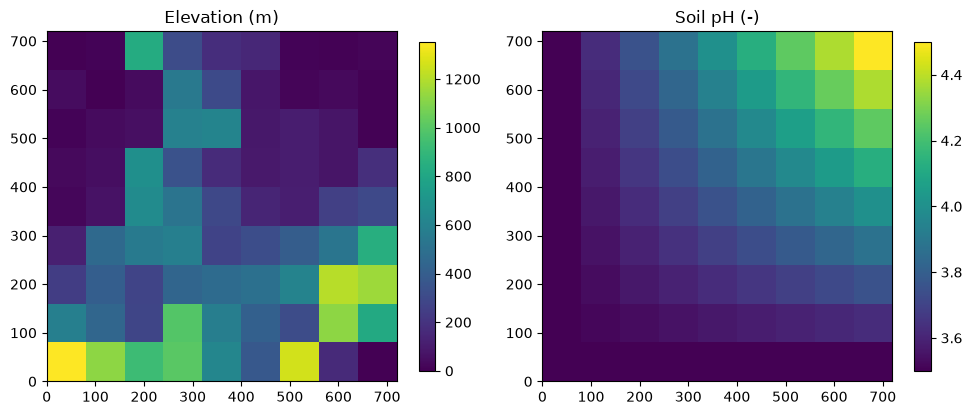
For some variables - such as elevation and soil pH - these are constant values for each grid cell that are used throughout the simulation.
Other variables, - such as precipitation and temperature - provide a time series that is provided which is used to that drive (or force) the behaviour of the model through time.
The code below plots both constant and forcing variables.
# Load the generated data files
inputs = xarray.load_dataset("ve_example/out/model_data.zarr", group="inputs")
inputs
<xarray.Dataset> Size: 175kB
Dimensions: (cell_id: 81, time_index: 24,
element: 3, pft: 2)
Coordinates:
* cell_id (cell_id) int64 648B 0 1 2 3 ... 78 79 80
x (cell_id) int32 324B 0 90 180 ... 630 720
y (cell_id) int32 324B 720 720 720 ... 0 0
* time_index (time_index) int64 192B 0 1 2 ... 22 23
* element (element) <U1 12B 'C' 'N' 'P'
* pft (pft) <U9 72B 'broadleaf' 'shrub'
Data variables: (12/41)
air_temperature_ref (cell_id, time_index) float64 16kB 22....
atmospheric_co2_ref (cell_id, time_index) float64 16kB 400...
atmospheric_pressure_ref (cell_id, time_index) float64 16kB 100...
clay_fraction (cell_id) float64 648B 0.27 ... 0.27
downward_longwave_radiation (cell_id, time_index) float64 16kB 406...
downward_shortwave_radiation (cell_id, time_index) int64 16kB 2040 ...
... ...
soil_p_pool_labile (cell_id) float64 648B 2.5e-05 ... 2.5...
soil_p_pool_primary (cell_id) float64 648B 0.001 ... 0.001
soil_p_pool_secondary (cell_id) float64 648B 0.005 ... 0.005
subcanopy_seedbank_biomass (cell_id) float64 648B 0.07 0.07 ... 0.07
subcanopy_vegetation_biomass (cell_id) float64 648B 0.07 0.07 ... 0.07
wind_speed_ref (cell_id, time_index) float64 16kB 0.1...- cell_id: 81
- time_index: 24
- element: 3
- pft: 2
- cell_id(cell_id)int640 1 2 3 4 5 6 ... 75 76 77 78 79 80
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80]) - x(cell_id)int320 90 180 270 ... 450 540 630 720
array([ 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720], dtype=int32) - y(cell_id)int32720 720 720 720 720 ... 0 0 0 0 0
array([720, 720, 720, 720, 720, 720, 720, 720, 720, 630, 630, 630, 630, 630, 630, 630, 630, 630, 540, 540, 540, 540, 540, 540, 540, 540, 540, 450, 450, 450, 450, 450, 450, 450, 450, 450, 360, 360, 360, 360, 360, 360, 360, 360, 360, 270, 270, 270, 270, 270, 270, 270, 270, 270, 180, 180, 180, 180, 180, 180, 180, 180, 180, 90, 90, 90, 90, 90, 90, 90, 90, 90, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32) - time_index(time_index)int640 1 2 3 4 5 6 ... 18 19 20 21 22 23
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]) - element(element)<U1'C' 'N' 'P'
array(['C', 'N', 'P'], dtype='<U1')
- pft(pft)<U9'broadleaf' 'shrub'
array(['broadleaf', 'shrub'], dtype='<U9')
- air_temperature_ref(cell_id, time_index)float6422.92 27.34 31.73 ... 14.98 17.25
- units :
- °C
- description :
- Air temperature at reference height (2m)
- unit :
- C
array([[22.92320799, 27.33726005, 31.72571926, ..., 12.71187496, 14.67839466, 17.97308933], [22.43249701, 27.57505607, 32.06472598, ..., 12.03237495, 14.45016414, 18.32018899], [22.42066596, 28.46029346, 31.73134617, ..., 12.70632852, 13.7281372 , 18.51628715], ..., [22.85555019, 27.26583056, 32.23931189, ..., 13.84998087, 14.13781432, 17.14029154], [22.5780398 , 28.97963397, 31.25914035, ..., 12.81795923, 13.60895361, 18.41070032], [23.11986464, 27.71284634, 31.44806144, ..., 14.07449815, 14.97627707, 17.25058122]], shape=(81, 24)) - atmospheric_co2_ref(cell_id, time_index)float64400.0 400.0 400.0 ... 400.0 400.0
- units :
- ppm
- description :
- Atmospheric CO2 concentration at reference height (above canopy)
- unit :
- ppm
array([[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], ..., [400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.]], shape=(81, 24)) - atmospheric_pressure_ref(cell_id, time_index)float64100.1 100.7 101.8 ... 100.2 100.9
- units :
- kPa
- description :
- Atmospheric pressure at reference height (2m)
- unit :
- kPa
array([[100.12915774, 100.70696051, 101.81209947, ..., 99.28911809, 100.22877698, 99.82598774], [101.61709194, 100.96351614, 101.9889127 , ..., 98.55747407, 99.81272126, 100.08742535], [100.91862927, 100.64823838, 101.95424075, ..., 100.32399296, 100.35779359, 100.38828998], ..., [101.47354612, 101.59024389, 101.1740057 , ..., 99.63108712, 99.79493477, 101.3809399 ], [100.56150941, 101.36044394, 102.51419506, ..., 100.37451715, 100.12958153, 100.42776646], [100.99499278, 101.66478406, 101.52033729, ..., 100.32618788, 100.1880621 , 100.90024182]], shape=(81, 24)) - clay_fraction(cell_id)float640.27 0.2863 0.3025 ... 0.27 0.27
- units :
- NA
- description :
- The fraction of clay in soil. This is a proportion between 0 and 1.
- unit :
- -
array([0.27 , 0.28625 , 0.3025 , 0.31875 , 0.335 , 0.35125 , 0.3675 , 0.38375 , 0.4 , 0.27 , 0.28421875, 0.2984375 , 0.31265625, 0.326875 , 0.34109375, 0.3553125 , 0.36953125, 0.38375 , 0.27 , 0.2821875 , 0.294375 , 0.3065625 , 0.31875 , 0.3309375 , 0.343125 , 0.3553125 , 0.3675 , 0.27 , 0.28015625, 0.2903125 , 0.30046875, 0.310625 , 0.32078125, 0.3309375 , 0.34109375, 0.35125 , 0.27 , 0.278125 , 0.28625 , 0.294375 , 0.3025 , 0.310625 , 0.31875 , 0.326875 , 0.335 , 0.27 , 0.27609375, 0.2821875 , 0.28828125, 0.294375 , 0.30046875, 0.3065625 , 0.31265625, 0.31875 , 0.27 , 0.2740625 , 0.278125 , 0.2821875 , 0.28625 , 0.2903125 , 0.294375 , 0.2984375 , 0.3025 , 0.27 , 0.27203125, 0.2740625 , 0.27609375, 0.278125 , 0.28015625, 0.2821875 , 0.28421875, 0.28625 , 0.27 , 0.27 , 0.27 , 0.27 , 0.27 , 0.27 , 0.27 , 0.27 , 0.27 ]) - downward_longwave_radiation(cell_id, time_index)float64406.3 414.8 416.5 ... 381.9 391.4
- unit :
- W m-2
- description :
- Top of canopy downward longwave radiation (DLR)
array([[406.26720283, 414.7536419 , 416.46335443, ..., 381.76632721, 383.09319942, 397.17175566], [390.30893932, 410.20391526, 425.96388455, ..., 379.70386254, 375.26676195, 386.93394604], [405.25612169, 406.82323497, 419.48070321, ..., 380.33350801, 377.73268413, 394.92350119], ..., [409.74440841, 414.82248494, 416.7940518 , ..., 383.9155347 , 382.40659095, 385.11395435], [410.95732437, 416.77197439, 424.6550798 , ..., 383.23810465, 390.85514155, 388.35022942], [392.76011403, 413.31724915, 428.25560288, ..., 375.88307913, 381.90376994, 391.38095581]], shape=(81, 24)) - downward_shortwave_radiation(cell_id, time_index)int642040 2040 2040 ... 2040 2040 2040
- unit :
- W m-2
- description :
- Top of canopy downward shortwave radiation (DSR)
array([[2040, 2040, 2040, ..., 2040, 2040, 2040], [2040, 2040, 2040, ..., 2040, 2040, 2040], [2040, 2040, 2040, ..., 2040, 2040, 2040], ..., [2040, 2040, 2040, ..., 2040, 2040, 2040], [2040, 2040, 2040, ..., 2040, 2040, 2040], [2040, 2040, 2040, ..., 2040, 2040, 2040]], shape=(81, 24)) - elevation(cell_id)float640.0 11.22 831.8 ... 159.3 0.0
- units :
- m
- description :
- Elevation above sea level
- unit :
- m
array([ 0. , 11.222, 831.778, 314. , 175.667, 152.778, 11.667, 9.889, 17.889, 46.333, 0. , 42.222, 548. , 301.444, 81. , 16. , 34.333, 8.111, 11. , 40.667, 54.667, 596. , 609.333, 88. , 107. , 76.667, 7.333, 35. , 52.667, 671.667, 338.333, 169. , 91.444, 110.667, 77.444, 183.556, 24. , 65.444, 655.111, 523. , 293.667, 138.556, 116. , 253.889, 299.222, 118. , 462.667, 552.667, 582. , 271.333, 318.667, 401. , 524.333, 850.333, 248.333, 404. , 277.222, 440. , 471.222, 500.111, 606.333, 1207.222, 1154.889, 583. , 446.111, 284.778, 992.333, 580.778, 415.111, 316.667, 1121.778, 820.222, 1353. , 1122.667, 928.667, 1008. , 619. , 374. , 1262. , 159.333, 0. ]) - fungal_fruiting_bodies(cell_id)float640.1 0.1375 0.175 ... 0.1 0.1 0.1
- units :
- kg C m^-2
- description :
- Density of fungal fruiting bodies growing from the litter and soil
- unit :
- kg C m^-2
array([0.1 , 0.1375 , 0.175 , 0.2125 , 0.25 , 0.2875 , 0.325 , 0.3625 , 0.4 , 0.1 , 0.1328125, 0.165625 , 0.1984375, 0.23125 , 0.2640625, 0.296875 , 0.3296875, 0.3625 , 0.1 , 0.128125 , 0.15625 , 0.184375 , 0.2125 , 0.240625 , 0.26875 , 0.296875 , 0.325 , 0.1 , 0.1234375, 0.146875 , 0.1703125, 0.19375 , 0.2171875, 0.240625 , 0.2640625, 0.2875 , 0.1 , 0.11875 , 0.1375 , 0.15625 , 0.175 , 0.19375 , 0.2125 , 0.23125 , 0.25 , 0.1 , 0.1140625, 0.128125 , 0.1421875, 0.15625 , 0.1703125, 0.184375 , 0.1984375, 0.2125 , 0.1 , 0.109375 , 0.11875 , 0.128125 , 0.1375 , 0.146875 , 0.15625 , 0.165625 , 0.175 , 0.1 , 0.1046875, 0.109375 , 0.1140625, 0.11875 , 0.1234375, 0.128125 , 0.1328125, 0.1375 , 0.1 , 0.1 , 0.1 , 0.1 , 0.1 , 0.1 , 0.1 , 0.1 , 0.1 ]) - lignin_above_structural(cell_id)float640.01 0.1212 0.2325 ... 0.01 0.01
- units :
- kg lignin C (kg C)^-1
- description :
- Proportion of above ground structural litter carbon which is lignin carbon
- unit :
- unitless
array([0.01 , 0.12125 , 0.2325 , 0.34375 , 0.455 , 0.56625 , 0.6775 , 0.78875 , 0.9 , 0.01 , 0.10734375, 0.2046875 , 0.30203125, 0.399375 , 0.49671875, 0.5940625 , 0.69140625, 0.78875 , 0.01 , 0.0934375 , 0.176875 , 0.2603125 , 0.34375 , 0.4271875 , 0.510625 , 0.5940625 , 0.6775 , 0.01 , 0.07953125, 0.1490625 , 0.21859375, 0.288125 , 0.35765625, 0.4271875 , 0.49671875, 0.56625 , 0.01 , 0.065625 , 0.12125 , 0.176875 , 0.2325 , 0.288125 , 0.34375 , 0.399375 , 0.455 , 0.01 , 0.05171875, 0.0934375 , 0.13515625, 0.176875 , 0.21859375, 0.2603125 , 0.30203125, 0.34375 , 0.01 , 0.0378125 , 0.065625 , 0.0934375 , 0.12125 , 0.1490625 , 0.176875 , 0.2046875 , 0.2325 , 0.01 , 0.02390625, 0.0378125 , 0.05171875, 0.065625 , 0.07953125, 0.0934375 , 0.10734375, 0.12125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - lignin_below_structural(cell_id)float640.01 0.1212 0.2325 ... 0.01 0.01
- units :
- kg lignin C (kg C)^-1
- description :
- Proportion of below ground structural litter carbon which is lignin carbon
- unit :
- unitless
array([0.01 , 0.12125 , 0.2325 , 0.34375 , 0.455 , 0.56625 , 0.6775 , 0.78875 , 0.9 , 0.01 , 0.10734375, 0.2046875 , 0.30203125, 0.399375 , 0.49671875, 0.5940625 , 0.69140625, 0.78875 , 0.01 , 0.0934375 , 0.176875 , 0.2603125 , 0.34375 , 0.4271875 , 0.510625 , 0.5940625 , 0.6775 , 0.01 , 0.07953125, 0.1490625 , 0.21859375, 0.288125 , 0.35765625, 0.4271875 , 0.49671875, 0.56625 , 0.01 , 0.065625 , 0.12125 , 0.176875 , 0.2325 , 0.288125 , 0.34375 , 0.399375 , 0.455 , 0.01 , 0.05171875, 0.0934375 , 0.13515625, 0.176875 , 0.21859375, 0.2603125 , 0.30203125, 0.34375 , 0.01 , 0.0378125 , 0.065625 , 0.0934375 , 0.12125 , 0.1490625 , 0.176875 , 0.2046875 , 0.2325 , 0.01 , 0.02390625, 0.0378125 , 0.05171875, 0.065625 , 0.07953125, 0.0934375 , 0.10734375, 0.12125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - lignin_woody(cell_id)float640.01 0.1212 0.2325 ... 0.01 0.01
- units :
- kg lignin C (kg C)^-1
- description :
- Proportion of dead wood carbon which is lignin carbon
- unit :
- unitless
array([0.01 , 0.12125 , 0.2325 , 0.34375 , 0.455 , 0.56625 , 0.6775 , 0.78875 , 0.9 , 0.01 , 0.10734375, 0.2046875 , 0.30203125, 0.399375 , 0.49671875, 0.5940625 , 0.69140625, 0.78875 , 0.01 , 0.0934375 , 0.176875 , 0.2603125 , 0.34375 , 0.4271875 , 0.510625 , 0.5940625 , 0.6775 , 0.01 , 0.07953125, 0.1490625 , 0.21859375, 0.288125 , 0.35765625, 0.4271875 , 0.49671875, 0.56625 , 0.01 , 0.065625 , 0.12125 , 0.176875 , 0.2325 , 0.288125 , 0.34375 , 0.399375 , 0.455 , 0.01 , 0.05171875, 0.0934375 , 0.13515625, 0.176875 , 0.21859375, 0.2603125 , 0.30203125, 0.34375 , 0.01 , 0.0378125 , 0.065625 , 0.0934375 , 0.12125 , 0.1490625 , 0.176875 , 0.2046875 , 0.2325 , 0.01 , 0.02390625, 0.0378125 , 0.05171875, 0.065625 , 0.07953125, 0.0934375 , 0.10734375, 0.12125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - litter_pool_above_metabolic_cnp(cell_id, element)float640.05 0.01 0.001 ... 0.05 0.01 0.001
- units :
- kg m^-2
- description :
- Above ground metabolic litter pool, carbon, nitrogen and phosphorus mass
- unit :
- kg m^-2
array([[0.05 , 0.01 , 0.001 ], [0.10625 , 0.01808511, 0.00180851], [0.1625 , 0.02407407, 0.00240741], [0.21875 , 0.02868852, 0.00286885], [0.275 , 0.03235294, 0.00323529], [0.33125 , 0.03533333, 0.00353333], [0.3875 , 0.03780488, 0.00378049], [0.44375 , 0.03988764, 0.00398876], [0.5 , 0.04166667, 0.00416667], [0.05 , 0.01 , 0.001 ], [0.09921875, 0.01720867, 0.00172087], [0.1484375 , 0.02272727, 0.00227273], [0.19765625, 0.02708779, 0.00270878], [0.246875 , 0.03062016, 0.00306202], [0.29609375, 0.03353982, 0.00335398], [0.3453125 , 0.03599349, 0.00359935], [0.39453125, 0.03808446, 0.00380845], [0.44375 , 0.03988764, 0.00398876], [0.05 , 0.01 , 0.001 ], [0.0921875 , 0.01629834, 0.00162983], ... [0.1484375 , 0.02272727, 0.00227273], [0.1625 , 0.02407407, 0.00240741], [0.05 , 0.01 , 0.001 ], [0.05703125, 0.01116208, 0.00111621], [0.0640625 , 0.01227545, 0.00122754], [0.07109375, 0.01334311, 0.00133431], [0.078125 , 0.01436782, 0.00143678], [0.08515625, 0.01535211, 0.00153521], [0.0921875 , 0.01629834, 0.00162983], [0.09921875, 0.01720867, 0.00172087], [0.10625 , 0.01808511, 0.00180851], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ], [0.05 , 0.01 , 0.001 ]]) - litter_pool_above_structural_cnp(cell_id, element)float640.05 0.002 0.0002 ... 0.002 0.0002
- units :
- kg m^-2
- description :
- Above ground structural litter pool, carbon, nitrogen and phosphorus mass
- unit :
- kg m^-2
array([[5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [1.06250000e-01, 3.61702128e-03, 3.61702128e-04], [1.62500000e-01, 4.81481481e-03, 4.81481481e-04], [2.18750000e-01, 5.73770492e-03, 5.73770492e-04], [2.75000000e-01, 6.47058824e-03, 6.47058824e-04], [3.31250000e-01, 7.06666667e-03, 7.06666667e-04], [3.87500000e-01, 7.56097561e-03, 7.56097561e-04], [4.43750000e-01, 7.97752809e-03, 7.97752809e-04], [5.00000000e-01, 8.33333333e-03, 8.33333333e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [9.92187500e-02, 3.44173442e-03, 3.44173442e-04], [1.48437500e-01, 4.54545455e-03, 4.54545455e-04], [1.97656250e-01, 5.41755889e-03, 5.41755889e-04], [2.46875000e-01, 6.12403101e-03, 6.12403101e-04], [2.96093750e-01, 6.70796460e-03, 6.70796460e-04], [3.45312500e-01, 7.19869707e-03, 7.19869707e-04], [3.94531250e-01, 7.61689291e-03, 7.61689291e-04], [4.43750000e-01, 7.97752809e-03, 7.97752809e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [9.21875000e-02, 3.25966851e-03, 3.25966851e-04], ... [1.48437500e-01, 4.54545455e-03, 4.54545455e-04], [1.62500000e-01, 4.81481481e-03, 4.81481481e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.70312500e-02, 2.23241590e-03, 2.23241590e-04], [6.40625000e-02, 2.45508982e-03, 2.45508982e-04], [7.10937500e-02, 2.66862170e-03, 2.66862170e-04], [7.81250000e-02, 2.87356322e-03, 2.87356322e-04], [8.51562500e-02, 3.07042254e-03, 3.07042254e-04], [9.21875000e-02, 3.25966851e-03, 3.25966851e-04], [9.92187500e-02, 3.44173442e-03, 3.44173442e-04], [1.06250000e-01, 3.61702128e-03, 3.61702128e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04], [5.00000000e-02, 2.00000000e-03, 2.00000000e-04]]) - litter_pool_below_metabolic_cnp(cell_id, element)float640.03 0.006 0.0006 ... 0.006 0.0006
- units :
- kg m^-2
- description :
- Below ground metabolic litter pool, carbon, nitrogen and phosphorus mass
- unit :
- kg m^-2
array([[0.03 , 0.006 , 0.0006 ], [0.03625 , 0.00617021, 0.00061702], [0.0425 , 0.0062963 , 0.00062963], [0.04875 , 0.00639344, 0.00063934], [0.055 , 0.00647059, 0.00064706], [0.06125 , 0.00653333, 0.00065333], [0.0675 , 0.00658537, 0.00065854], [0.07375 , 0.00662921, 0.00066292], [0.08 , 0.00666667, 0.00066667], [0.03 , 0.006 , 0.0006 ], [0.03546875, 0.00615176, 0.00061518], [0.0409375 , 0.00626794, 0.00062679], [0.04640625, 0.00635974, 0.00063597], [0.051875 , 0.00643411, 0.00064341], [0.05734375, 0.00649558, 0.00064956], [0.0628125 , 0.00654723, 0.00065472], [0.06828125, 0.00659125, 0.00065913], [0.07375 , 0.00662921, 0.00066292], [0.03 , 0.006 , 0.0006 ], [0.0346875 , 0.0061326 , 0.00061326], ... [0.0409375 , 0.00626794, 0.00062679], [0.0425 , 0.0062963 , 0.00062963], [0.03 , 0.006 , 0.0006 ], [0.03078125, 0.00602446, 0.00060245], [0.0315625 , 0.0060479 , 0.00060479], [0.03234375, 0.00607038, 0.00060704], [0.033125 , 0.00609195, 0.0006092 ], [0.03390625, 0.00611268, 0.00061127], [0.0346875 , 0.0061326 , 0.00061326], [0.03546875, 0.00615176, 0.00061518], [0.03625 , 0.00617021, 0.00061702], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ], [0.03 , 0.006 , 0.0006 ]]) - litter_pool_below_structural_cnp(cell_id, element)float640.05 0.002 0.0002 ... 0.002 0.0002
- units :
- kg m^-2
- description :
- Below ground structural litter pool, carbon, nitrogen and phosphorus mass
- unit :
- kg m^-2
array([[0.05 , 0.002 , 0.0002 ], [0.059375 , 0.00202128, 0.00020213], [0.06875 , 0.00203704, 0.0002037 ], [0.078125 , 0.00204918, 0.00020492], [0.0875 , 0.00205882, 0.00020588], [0.096875 , 0.00206667, 0.00020667], [0.10625 , 0.00207317, 0.00020732], [0.115625 , 0.00207865, 0.00020787], [0.125 , 0.00208333, 0.00020833], [0.05 , 0.002 , 0.0002 ], [0.05820313, 0.00201897, 0.0002019 ], [0.06640625, 0.00203349, 0.00020335], [0.07460938, 0.00204497, 0.0002045 ], [0.0828125 , 0.00205426, 0.00020543], [0.09101563, 0.00206195, 0.00020619], [0.09921875, 0.0020684 , 0.00020684], [0.10742188, 0.00207391, 0.00020739], [0.115625 , 0.00207865, 0.00020787], [0.05 , 0.002 , 0.0002 ], [0.05703125, 0.00201657, 0.00020166], ... [0.06640625, 0.00203349, 0.00020335], [0.06875 , 0.00203704, 0.0002037 ], [0.05 , 0.002 , 0.0002 ], [0.05117188, 0.00200306, 0.00020031], [0.05234375, 0.00200599, 0.0002006 ], [0.05351563, 0.0020088 , 0.00020088], [0.0546875 , 0.00201149, 0.00020115], [0.05585938, 0.00201408, 0.00020141], [0.05703125, 0.00201657, 0.00020166], [0.05820313, 0.00201897, 0.0002019 ], [0.059375 , 0.00202128, 0.00020213], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ], [0.05 , 0.002 , 0.0002 ]]) - litter_pool_woody_cnp(cell_id, element)float644.75 0.1583 ... 0.1583 0.01583
- units :
- kg m^-2
- description :
- Woody litter pool, carbon, nitrogen and phosphorus mass
- unit :
- kg m^-2
array([[ 4.75 , 0.15833333, 0.01583333], [ 5.65625 , 0.16160714, 0.01616071], [ 6.5625 , 0.1640625 , 0.01640625], [ 7.46875 , 0.16597222, 0.01659722], [ 8.375 , 0.1675 , 0.01675 ], [ 9.28125 , 0.16875 , 0.016875 ], [10.1875 , 0.16979167, 0.01697917], [11.09375 , 0.17067308, 0.01706731], [12. , 0.17142857, 0.01714286], [ 4.75 , 0.15833333, 0.01583333], [ 5.54296875, 0.16125 , 0.016125 ], [ 6.3359375 , 0.16350806, 0.01635081], [ 7.12890625, 0.16530797, 0.0165308 ], [ 7.921875 , 0.16677632, 0.01667763], [ 8.71484375, 0.16799699, 0.0167997 ], [ 9.5078125 , 0.16902778, 0.01690278], [10.30078125, 0.16990979, 0.01699098], [11.09375 , 0.17067308, 0.01706731], [ 4.75 , 0.15833333, 0.01583333], [ 5.4296875 , 0.16087963, 0.01608796], ... [ 6.3359375 , 0.16350806, 0.01635081], [ 6.5625 , 0.1640625 , 0.01640625], [ 4.75 , 0.15833333, 0.01583333], [ 4.86328125, 0.15880102, 0.0158801 ], [ 4.9765625 , 0.15925 , 0.015925 ], [ 5.08984375, 0.15968137, 0.01596814], [ 5.203125 , 0.16009615, 0.01600962], [ 5.31640625, 0.16049528, 0.01604953], [ 5.4296875 , 0.16087963, 0.01608796], [ 5.54296875, 0.16125 , 0.016125 ], [ 5.65625 , 0.16160714, 0.01616071], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333], [ 4.75 , 0.15833333, 0.01583333]]) - mean_annual_temperature(cell_id, time_index)float6423.86 22.96 24.92 ... 20.42 21.36
- units :
- °C
- description :
- Mean annual temperature = temperature of deepest soil layer
- unit :
- C
array([[23.8579326 , 22.96331036, 24.92414797, ..., 20.87582454, 20.97662124, 21.94381206], [23.56634292, 23.99476484, 24.58861317, ..., 20.75651208, 21.22860502, 21.77117719], [22.92189207, 24.23672699, 24.77108509, ..., 20.16972266, 20.09999877, 22.38686651], ..., [23.29639025, 23.92764671, 25.21061844, ..., 20.64930647, 20.86828842, 22.01943151], [23.45819261, 24.61301007, 24.18558912, ..., 20.37848436, 21.31891036, 21.21894303], [23.49090457, 23.49764672, 25.17841768, ..., 21.43430547, 20.42310625, 21.36305332]], shape=(81, 24)) - pH(cell_id)float643.5 3.625 3.75 ... 3.5 3.5 3.5
- units :
- pH
- description :
- Soil pH values for each grid cell
- unit :
- pH
array([3.5 , 3.625 , 3.75 , 3.875 , 4. , 4.125 , 4.25 , 4.375 , 4.5 , 3.5 , 3.609375, 3.71875 , 3.828125, 3.9375 , 4.046875, 4.15625 , 4.265625, 4.375 , 3.5 , 3.59375 , 3.6875 , 3.78125 , 3.875 , 3.96875 , 4.0625 , 4.15625 , 4.25 , 3.5 , 3.578125, 3.65625 , 3.734375, 3.8125 , 3.890625, 3.96875 , 4.046875, 4.125 , 3.5 , 3.5625 , 3.625 , 3.6875 , 3.75 , 3.8125 , 3.875 , 3.9375 , 4. , 3.5 , 3.546875, 3.59375 , 3.640625, 3.6875 , 3.734375, 3.78125 , 3.828125, 3.875 , 3.5 , 3.53125 , 3.5625 , 3.59375 , 3.625 , 3.65625 , 3.6875 , 3.71875 , 3.75 , 3.5 , 3.515625, 3.53125 , 3.546875, 3.5625 , 3.578125, 3.59375 , 3.609375, 3.625 , 3.5 , 3.5 , 3.5 , 3.5 , 3.5 , 3.5 , 3.5 , 3.5 , 3.5 ]) - plant_pft_propagules(cell_id, pft)int64100 100 100 100 ... 100 100 100 100
- unit :
- count
- description :
- Per cell counts of propagules for each plant functional type
array([[100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], ... [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100], [100, 100]]) - precipitation(cell_id, time_index)float64251.6 379.9 626.6 ... 0.0 0.0 0.0
- units :
- mm
- description :
- Precipitation input at the top of the canopy
- unit :
- mm
array([[251.5812999 , 379.93455291, 626.59189539, ..., 0. , 0. , 31.66191698], [249.38663955, 378.97248327, 594.96869526, ..., 0. , 0. , 39.62479443], [229.94329074, 443.99066142, 607.21868131, ..., 0. , 0. , 0. ], ..., [203.64441997, 462.85986626, 544.55372695, ..., 0. , 0. , 0. ], [185.09274426, 458.90887372, 592.69870621, ..., 0. , 0. , 0. ], [255.28981254, 414.37306839, 589.54523377, ..., 0. , 0. , 0. ]], shape=(81, 24)) - relative_humidity_ref(cell_id, time_index)float6484.26 92.26 100.0 ... 71.38 78.46
- units :
- %
- description :
- Relative humidity at reference height (2m)
- unit :
- %
array([[ 84.26389887, 92.26397245, 100. , ..., 67.60271652, 70.63312198, 78.31734493], [ 84.31929038, 93.49008521, 94.08707925, ..., 70.03003401, 68.59674369, 77.86915833], [ 87.00965838, 91.87819927, 98.07772152, ..., 68.37705056, 71.51940834, 79.48430283], ..., [ 83.35697745, 90.48482703, 94.51215519, ..., 70.2203247 , 73.43324227, 74.82441758], [ 83.72106275, 92.57059903, 96.43299182, ..., 68.44933234, 70.31880817, 78.06218489], [ 84.49945442, 89.96444247, 98.00204324, ..., 69.9206229 , 71.38228944, 78.45826725]], shape=(81, 24)) - soil_c_pool_arbuscular_mycorrhiza(cell_id)float640.0015 0.001937 ... 0.0015 0.0015
- units :
- kg C m^-3
- description :
- Soil arbuscular mycorrhizal fungal biomass (carbon) pool
- unit :
- kg{C} m^-3
array([0.0015 , 0.0019375 , 0.002375 , 0.0028125 , 0.00325 , 0.0036875 , 0.004125 , 0.0045625 , 0.005 , 0.0015 , 0.00188281, 0.00226563, 0.00264844, 0.00303125, 0.00341406, 0.00379687, 0.00417969, 0.0045625 , 0.0015 , 0.00182813, 0.00215625, 0.00248438, 0.0028125 , 0.00314063, 0.00346875, 0.00379687, 0.004125 , 0.0015 , 0.00177344, 0.00204688, 0.00232031, 0.00259375, 0.00286719, 0.00314063, 0.00341406, 0.0036875 , 0.0015 , 0.00171875, 0.0019375 , 0.00215625, 0.002375 , 0.00259375, 0.0028125 , 0.00303125, 0.00325 , 0.0015 , 0.00166406, 0.00182813, 0.00199219, 0.00215625, 0.00232031, 0.00248438, 0.00264844, 0.0028125 , 0.0015 , 0.00160938, 0.00171875, 0.00182813, 0.0019375 , 0.00204688, 0.00215625, 0.00226563, 0.002375 , 0.0015 , 0.00155469, 0.00160938, 0.00166406, 0.00171875, 0.00177344, 0.00182813, 0.00188281, 0.0019375 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 ]) - soil_c_pool_bacteria(cell_id)float640.0015 0.001937 ... 0.0015 0.0015
- units :
- kg C m^-3
- description :
- Soil bacterial biomass (carbon) pool
- unit :
- kg{C} m^-3
array([0.0015 , 0.0019375 , 0.002375 , 0.0028125 , 0.00325 , 0.0036875 , 0.004125 , 0.0045625 , 0.005 , 0.0015 , 0.00188281, 0.00226563, 0.00264844, 0.00303125, 0.00341406, 0.00379687, 0.00417969, 0.0045625 , 0.0015 , 0.00182813, 0.00215625, 0.00248438, 0.0028125 , 0.00314063, 0.00346875, 0.00379687, 0.004125 , 0.0015 , 0.00177344, 0.00204688, 0.00232031, 0.00259375, 0.00286719, 0.00314063, 0.00341406, 0.0036875 , 0.0015 , 0.00171875, 0.0019375 , 0.00215625, 0.002375 , 0.00259375, 0.0028125 , 0.00303125, 0.00325 , 0.0015 , 0.00166406, 0.00182813, 0.00199219, 0.00215625, 0.00232031, 0.00248438, 0.00264844, 0.0028125 , 0.0015 , 0.00160938, 0.00171875, 0.00182813, 0.0019375 , 0.00204688, 0.00215625, 0.00226563, 0.002375 , 0.0015 , 0.00155469, 0.00160938, 0.00166406, 0.00171875, 0.00177344, 0.00182813, 0.00188281, 0.0019375 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 ]) - soil_c_pool_ectomycorrhiza(cell_id)float640.0015 0.001937 ... 0.0015 0.0015
- units :
- kg C m^-3
- description :
- Soil ectomycorrhizal fungal biomass (carbon) pool
- unit :
- kg{C} m^-3
array([0.0015 , 0.0019375 , 0.002375 , 0.0028125 , 0.00325 , 0.0036875 , 0.004125 , 0.0045625 , 0.005 , 0.0015 , 0.00188281, 0.00226563, 0.00264844, 0.00303125, 0.00341406, 0.00379687, 0.00417969, 0.0045625 , 0.0015 , 0.00182813, 0.00215625, 0.00248438, 0.0028125 , 0.00314063, 0.00346875, 0.00379687, 0.004125 , 0.0015 , 0.00177344, 0.00204688, 0.00232031, 0.00259375, 0.00286719, 0.00314063, 0.00341406, 0.0036875 , 0.0015 , 0.00171875, 0.0019375 , 0.00215625, 0.002375 , 0.00259375, 0.0028125 , 0.00303125, 0.00325 , 0.0015 , 0.00166406, 0.00182813, 0.00199219, 0.00215625, 0.00232031, 0.00248438, 0.00264844, 0.0028125 , 0.0015 , 0.00160938, 0.00171875, 0.00182813, 0.0019375 , 0.00204688, 0.00215625, 0.00226563, 0.002375 , 0.0015 , 0.00155469, 0.00160938, 0.00166406, 0.00171875, 0.00177344, 0.00182813, 0.00188281, 0.0019375 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 ]) - soil_c_pool_saprotrophic_fungi(cell_id)float640.0015 0.001937 ... 0.0015 0.0015
- units :
- kg C m^-3
- description :
- Soil saprotrophic fungal biomass (carbon) pool
- unit :
- kg{C} m^-3
array([0.0015 , 0.0019375 , 0.002375 , 0.0028125 , 0.00325 , 0.0036875 , 0.004125 , 0.0045625 , 0.005 , 0.0015 , 0.00188281, 0.00226563, 0.00264844, 0.00303125, 0.00341406, 0.00379687, 0.00417969, 0.0045625 , 0.0015 , 0.00182813, 0.00215625, 0.00248438, 0.0028125 , 0.00314063, 0.00346875, 0.00379687, 0.004125 , 0.0015 , 0.00177344, 0.00204688, 0.00232031, 0.00259375, 0.00286719, 0.00314063, 0.00341406, 0.0036875 , 0.0015 , 0.00171875, 0.0019375 , 0.00215625, 0.002375 , 0.00259375, 0.0028125 , 0.00303125, 0.00325 , 0.0015 , 0.00166406, 0.00182813, 0.00199219, 0.00215625, 0.00232031, 0.00248438, 0.00264844, 0.0028125 , 0.0015 , 0.00160938, 0.00171875, 0.00182813, 0.0019375 , 0.00204688, 0.00215625, 0.00226563, 0.002375 , 0.0015 , 0.00155469, 0.00160938, 0.00166406, 0.00171875, 0.00177344, 0.00182813, 0.00188281, 0.0019375 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 , 0.0015 ]) - soil_cnp_pool_lmwc(cell_id, element)float640.005 0.00025 ... 0.00025 1e-05
- units :
- kg m^-3
- description :
- Soil low molecular weight organic pool. Carbon, nitrogen and phosphorous content
- unit :
- kg m^-3
array([[5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.6250000e-03, 2.8125000e-04, 1.1250000e-05], [6.2500000e-03, 3.1250000e-04, 1.2500000e-05], [6.8750000e-03, 3.4375000e-04, 1.3750000e-05], [7.5000000e-03, 3.7500000e-04, 1.5000000e-05], [8.1250000e-03, 4.0625000e-04, 1.6250000e-05], [8.7500000e-03, 4.3750000e-04, 1.7500000e-05], [9.3750000e-03, 4.6875000e-04, 1.8750000e-05], [1.0000000e-02, 5.0000000e-04, 2.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.5468750e-03, 2.7734375e-04, 1.1093750e-05], [6.0937500e-03, 3.0468750e-04, 1.2187500e-05], [6.6406250e-03, 3.3203125e-04, 1.3281250e-05], [7.1875000e-03, 3.5937500e-04, 1.4375000e-05], [7.7343750e-03, 3.8671875e-04, 1.5468750e-05], [8.2812500e-03, 4.1406250e-04, 1.6562500e-05], [8.8281250e-03, 4.4140625e-04, 1.7656250e-05], [9.3750000e-03, 4.6875000e-04, 1.8750000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.4687500e-03, 2.7343750e-04, 1.0937500e-05], ... [6.0937500e-03, 3.0468750e-04, 1.2187500e-05], [6.2500000e-03, 3.1250000e-04, 1.2500000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0781250e-03, 2.5390625e-04, 1.0156250e-05], [5.1562500e-03, 2.5781250e-04, 1.0312500e-05], [5.2343750e-03, 2.6171875e-04, 1.0468750e-05], [5.3125000e-03, 2.6562500e-04, 1.0625000e-05], [5.3906250e-03, 2.6953125e-04, 1.0781250e-05], [5.4687500e-03, 2.7343750e-04, 1.0937500e-05], [5.5468750e-03, 2.7734375e-04, 1.1093750e-05], [5.6250000e-03, 2.8125000e-04, 1.1250000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05], [5.0000000e-03, 2.5000000e-04, 1.0000000e-05]]) - soil_cnp_pool_maom(cell_id, element)float641.0 0.2 0.008 ... 1.0 0.2 0.008
- units :
- kg m^-3
- description :
- Soil mineral associated organic matter pool. Carbon, nitrogen and phosphorous content
- unit :
- kg m^-3
array([[1. , 0.2 , 0.008 ], [1.25 , 0.25 , 0.01 ], [1.5 , 0.3 , 0.012 ], [1.75 , 0.35 , 0.014 ], [2. , 0.4 , 0.016 ], [2.25 , 0.45 , 0.018 ], [2.5 , 0.5 , 0.02 ], [2.75 , 0.55 , 0.022 ], [3. , 0.6 , 0.024 ], [1. , 0.2 , 0.008 ], [1.21875, 0.24375, 0.00975], [1.4375 , 0.2875 , 0.0115 ], [1.65625, 0.33125, 0.01325], [1.875 , 0.375 , 0.015 ], [2.09375, 0.41875, 0.01675], [2.3125 , 0.4625 , 0.0185 ], [2.53125, 0.50625, 0.02025], [2.75 , 0.55 , 0.022 ], [1. , 0.2 , 0.008 ], [1.1875 , 0.2375 , 0.0095 ], ... [1.4375 , 0.2875 , 0.0115 ], [1.5 , 0.3 , 0.012 ], [1. , 0.2 , 0.008 ], [1.03125, 0.20625, 0.00825], [1.0625 , 0.2125 , 0.0085 ], [1.09375, 0.21875, 0.00875], [1.125 , 0.225 , 0.009 ], [1.15625, 0.23125, 0.00925], [1.1875 , 0.2375 , 0.0095 ], [1.21875, 0.24375, 0.00975], [1.25 , 0.25 , 0.01 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ], [1. , 0.2 , 0.008 ]]) - soil_cnp_pool_necromass(cell_id, element)float640.00015 3e-05 ... 3e-05 1.2e-06
- units :
- kg m^-3
- description :
- Necrotic organic matter pool. Carbon, nitrogen and phosphorous content
- unit :
- kg m^-3
array([[1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.9375000e-04, 3.8750000e-05, 1.5500000e-06], [2.3750000e-04, 4.7500000e-05, 1.9000000e-06], [2.8125000e-04, 5.6250000e-05, 2.2500000e-06], [3.2500000e-04, 6.5000000e-05, 2.6000000e-06], [3.6875000e-04, 7.3750000e-05, 2.9500000e-06], [4.1250000e-04, 8.2500000e-05, 3.3000000e-06], [4.5625000e-04, 9.1250000e-05, 3.6500000e-06], [5.0000000e-04, 1.0000000e-04, 4.0000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.8828125e-04, 3.7656250e-05, 1.5062500e-06], [2.2656250e-04, 4.5312500e-05, 1.8125000e-06], [2.6484375e-04, 5.2968750e-05, 2.1187500e-06], [3.0312500e-04, 6.0625000e-05, 2.4250000e-06], [3.4140625e-04, 6.8281250e-05, 2.7312500e-06], [3.7968750e-04, 7.5937500e-05, 3.0375000e-06], [4.1796875e-04, 8.3593750e-05, 3.3437500e-06], [4.5625000e-04, 9.1250000e-05, 3.6500000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.8281250e-04, 3.6562500e-05, 1.4625000e-06], ... [2.2656250e-04, 4.5312500e-05, 1.8125000e-06], [2.3750000e-04, 4.7500000e-05, 1.9000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5546875e-04, 3.1093750e-05, 1.2437500e-06], [1.6093750e-04, 3.2187500e-05, 1.2875000e-06], [1.6640625e-04, 3.3281250e-05, 1.3312500e-06], [1.7187500e-04, 3.4375000e-05, 1.3750000e-06], [1.7734375e-04, 3.5468750e-05, 1.4187500e-06], [1.8281250e-04, 3.6562500e-05, 1.4625000e-06], [1.8828125e-04, 3.7656250e-05, 1.5062500e-06], [1.9375000e-04, 3.8750000e-05, 1.5500000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06], [1.5000000e-04, 3.0000000e-05, 1.2000000e-06]]) - soil_cnp_pool_pom(cell_id, element)float640.1 0.00075 3e-05 ... 0.00075 3e-05
- units :
- kg m^-3
- description :
- Particulate organic matter pool. Carbon, nitrogen and phosphorous content
- unit :
- kg m^-3
array([[1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [2.12500000e-01, 8.43750000e-04, 3.37500000e-05], [3.25000000e-01, 9.37500000e-04, 3.75000000e-05], [4.37500000e-01, 1.03125000e-03, 4.12500000e-05], [5.50000000e-01, 1.12500000e-03, 4.50000000e-05], [6.62500000e-01, 1.21875000e-03, 4.87500000e-05], [7.75000000e-01, 1.31250000e-03, 5.25000000e-05], [8.87500000e-01, 1.40625000e-03, 5.62500000e-05], [1.00000000e+00, 1.50000000e-03, 6.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.98437500e-01, 8.32031250e-04, 3.32812500e-05], [2.96875000e-01, 9.14062500e-04, 3.65625000e-05], [3.95312500e-01, 9.96093750e-04, 3.98437500e-05], [4.93750000e-01, 1.07812500e-03, 4.31250000e-05], [5.92187500e-01, 1.16015625e-03, 4.64062500e-05], [6.90625000e-01, 1.24218750e-03, 4.96875000e-05], [7.89062500e-01, 1.32421875e-03, 5.29687500e-05], [8.87500000e-01, 1.40625000e-03, 5.62500000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.84375000e-01, 8.20312500e-04, 3.28125000e-05], ... [2.96875000e-01, 9.14062500e-04, 3.65625000e-05], [3.25000000e-01, 9.37500000e-04, 3.75000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.14062500e-01, 7.61718750e-04, 3.04687500e-05], [1.28125000e-01, 7.73437500e-04, 3.09375000e-05], [1.42187500e-01, 7.85156250e-04, 3.14062500e-05], [1.56250000e-01, 7.96875000e-04, 3.18750000e-05], [1.70312500e-01, 8.08593750e-04, 3.23437500e-05], [1.84375000e-01, 8.20312500e-04, 3.28125000e-05], [1.98437500e-01, 8.32031250e-04, 3.32812500e-05], [2.12500000e-01, 8.43750000e-04, 3.37500000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05], [1.00000000e-01, 7.50000000e-04, 3.00000000e-05]]) - soil_enzyme_maom_bacteria(cell_id)float640.01 0.07125 0.1325 ... 0.01 0.01
- units :
- kg C m^-3
- description :
- Amount of bacterial enzyme class which breaks down mineral associated organic matter
- unit :
- kg{C} m^-3
array([0.01 , 0.07125 , 0.1325 , 0.19375 , 0.255 , 0.31625 , 0.3775 , 0.43875 , 0.5 , 0.01 , 0.06359375, 0.1171875 , 0.17078125, 0.224375 , 0.27796875, 0.3315625 , 0.38515625, 0.43875 , 0.01 , 0.0559375 , 0.101875 , 0.1478125 , 0.19375 , 0.2396875 , 0.285625 , 0.3315625 , 0.3775 , 0.01 , 0.04828125, 0.0865625 , 0.12484375, 0.163125 , 0.20140625, 0.2396875 , 0.27796875, 0.31625 , 0.01 , 0.040625 , 0.07125 , 0.101875 , 0.1325 , 0.163125 , 0.19375 , 0.224375 , 0.255 , 0.01 , 0.03296875, 0.0559375 , 0.07890625, 0.101875 , 0.12484375, 0.1478125 , 0.17078125, 0.19375 , 0.01 , 0.0253125 , 0.040625 , 0.0559375 , 0.07125 , 0.0865625 , 0.101875 , 0.1171875 , 0.1325 , 0.01 , 0.01765625, 0.0253125 , 0.03296875, 0.040625 , 0.04828125, 0.0559375 , 0.06359375, 0.07125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - soil_enzyme_maom_fungi(cell_id)float640.01 0.07125 0.1325 ... 0.01 0.01
- units :
- kg C m^-3
- description :
- Amount of fungal enzyme class which breaks down mineral associated organic matter
- unit :
- kg{C} m^-3
array([0.01 , 0.07125 , 0.1325 , 0.19375 , 0.255 , 0.31625 , 0.3775 , 0.43875 , 0.5 , 0.01 , 0.06359375, 0.1171875 , 0.17078125, 0.224375 , 0.27796875, 0.3315625 , 0.38515625, 0.43875 , 0.01 , 0.0559375 , 0.101875 , 0.1478125 , 0.19375 , 0.2396875 , 0.285625 , 0.3315625 , 0.3775 , 0.01 , 0.04828125, 0.0865625 , 0.12484375, 0.163125 , 0.20140625, 0.2396875 , 0.27796875, 0.31625 , 0.01 , 0.040625 , 0.07125 , 0.101875 , 0.1325 , 0.163125 , 0.19375 , 0.224375 , 0.255 , 0.01 , 0.03296875, 0.0559375 , 0.07890625, 0.101875 , 0.12484375, 0.1478125 , 0.17078125, 0.19375 , 0.01 , 0.0253125 , 0.040625 , 0.0559375 , 0.07125 , 0.0865625 , 0.101875 , 0.1171875 , 0.1325 , 0.01 , 0.01765625, 0.0253125 , 0.03296875, 0.040625 , 0.04828125, 0.0559375 , 0.06359375, 0.07125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - soil_enzyme_pom_bacteria(cell_id)float640.01 0.07125 0.1325 ... 0.01 0.01
- units :
- kg C m^-3
- description :
- Amount of bacterial enzyme class which breaks down particulate organic matter
- unit :
- kg{C} m^-3
array([0.01 , 0.07125 , 0.1325 , 0.19375 , 0.255 , 0.31625 , 0.3775 , 0.43875 , 0.5 , 0.01 , 0.06359375, 0.1171875 , 0.17078125, 0.224375 , 0.27796875, 0.3315625 , 0.38515625, 0.43875 , 0.01 , 0.0559375 , 0.101875 , 0.1478125 , 0.19375 , 0.2396875 , 0.285625 , 0.3315625 , 0.3775 , 0.01 , 0.04828125, 0.0865625 , 0.12484375, 0.163125 , 0.20140625, 0.2396875 , 0.27796875, 0.31625 , 0.01 , 0.040625 , 0.07125 , 0.101875 , 0.1325 , 0.163125 , 0.19375 , 0.224375 , 0.255 , 0.01 , 0.03296875, 0.0559375 , 0.07890625, 0.101875 , 0.12484375, 0.1478125 , 0.17078125, 0.19375 , 0.01 , 0.0253125 , 0.040625 , 0.0559375 , 0.07125 , 0.0865625 , 0.101875 , 0.1171875 , 0.1325 , 0.01 , 0.01765625, 0.0253125 , 0.03296875, 0.040625 , 0.04828125, 0.0559375 , 0.06359375, 0.07125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - soil_enzyme_pom_fungi(cell_id)float640.01 0.07125 0.1325 ... 0.01 0.01
- units :
- kg C m^-3
- description :
- Amount of fungal enzyme class which breaks down particulate organic matter
- unit :
- kg{C} m^-3
array([0.01 , 0.07125 , 0.1325 , 0.19375 , 0.255 , 0.31625 , 0.3775 , 0.43875 , 0.5 , 0.01 , 0.06359375, 0.1171875 , 0.17078125, 0.224375 , 0.27796875, 0.3315625 , 0.38515625, 0.43875 , 0.01 , 0.0559375 , 0.101875 , 0.1478125 , 0.19375 , 0.2396875 , 0.285625 , 0.3315625 , 0.3775 , 0.01 , 0.04828125, 0.0865625 , 0.12484375, 0.163125 , 0.20140625, 0.2396875 , 0.27796875, 0.31625 , 0.01 , 0.040625 , 0.07125 , 0.101875 , 0.1325 , 0.163125 , 0.19375 , 0.224375 , 0.255 , 0.01 , 0.03296875, 0.0559375 , 0.07890625, 0.101875 , 0.12484375, 0.1478125 , 0.17078125, 0.19375 , 0.01 , 0.0253125 , 0.040625 , 0.0559375 , 0.07125 , 0.0865625 , 0.101875 , 0.1171875 , 0.1325 , 0.01 , 0.01765625, 0.0253125 , 0.03296875, 0.040625 , 0.04828125, 0.0559375 , 0.06359375, 0.07125 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 ]) - soil_n_pool_ammonium(cell_id)float640.001 0.0015 0.002 ... 0.001 0.001
- units :
- kg N m^-3
- description :
- Amount of nitrogen contained in the soil ammonium (NH4+) pool
- unit :
- kg{N} m^-3
array([0.001 , 0.0015 , 0.002 , 0.0025 , 0.003 , 0.0035 , 0.004 , 0.0045 , 0.005 , 0.001 , 0.0014375, 0.001875 , 0.0023125, 0.00275 , 0.0031875, 0.003625 , 0.0040625, 0.0045 , 0.001 , 0.001375 , 0.00175 , 0.002125 , 0.0025 , 0.002875 , 0.00325 , 0.003625 , 0.004 , 0.001 , 0.0013125, 0.001625 , 0.0019375, 0.00225 , 0.0025625, 0.002875 , 0.0031875, 0.0035 , 0.001 , 0.00125 , 0.0015 , 0.00175 , 0.002 , 0.00225 , 0.0025 , 0.00275 , 0.003 , 0.001 , 0.0011875, 0.001375 , 0.0015625, 0.00175 , 0.0019375, 0.002125 , 0.0023125, 0.0025 , 0.001 , 0.001125 , 0.00125 , 0.001375 , 0.0015 , 0.001625 , 0.00175 , 0.001875 , 0.002 , 0.001 , 0.0010625, 0.001125 , 0.0011875, 0.00125 , 0.0013125, 0.001375 , 0.0014375, 0.0015 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 ]) - soil_n_pool_nitrate(cell_id)float640.001 0.0015 0.002 ... 0.001 0.001
- units :
- kg N m^-3
- description :
- Amount of nitrogen contained in the soil nitrate (NO3-) pool
- unit :
- kg{N} m^-3
array([0.001 , 0.0015 , 0.002 , 0.0025 , 0.003 , 0.0035 , 0.004 , 0.0045 , 0.005 , 0.001 , 0.0014375, 0.001875 , 0.0023125, 0.00275 , 0.0031875, 0.003625 , 0.0040625, 0.0045 , 0.001 , 0.001375 , 0.00175 , 0.002125 , 0.0025 , 0.002875 , 0.00325 , 0.003625 , 0.004 , 0.001 , 0.0013125, 0.001625 , 0.0019375, 0.00225 , 0.0025625, 0.002875 , 0.0031875, 0.0035 , 0.001 , 0.00125 , 0.0015 , 0.00175 , 0.002 , 0.00225 , 0.0025 , 0.00275 , 0.003 , 0.001 , 0.0011875, 0.001375 , 0.0015625, 0.00175 , 0.0019375, 0.002125 , 0.0023125, 0.0025 , 0.001 , 0.001125 , 0.00125 , 0.001375 , 0.0015 , 0.001625 , 0.00175 , 0.001875 , 0.002 , 0.001 , 0.0010625, 0.001125 , 0.0011875, 0.00125 , 0.0013125, 0.001375 , 0.0014375, 0.0015 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 ]) - soil_p_pool_labile(cell_id)float642.5e-05 2.813e-05 ... 2.5e-05
- units :
- kg P m^-3
- description :
- Amount of inorganic phosphorus that is in a labile form
- unit :
- kg{P} m^-3
array([2.5000000e-05, 2.8125000e-05, 3.1250000e-05, 3.4375000e-05, 3.7500000e-05, 4.0625000e-05, 4.3750000e-05, 4.6875000e-05, 5.0000000e-05, 2.5000000e-05, 2.7734375e-05, 3.0468750e-05, 3.3203125e-05, 3.5937500e-05, 3.8671875e-05, 4.1406250e-05, 4.4140625e-05, 4.6875000e-05, 2.5000000e-05, 2.7343750e-05, 2.9687500e-05, 3.2031250e-05, 3.4375000e-05, 3.6718750e-05, 3.9062500e-05, 4.1406250e-05, 4.3750000e-05, 2.5000000e-05, 2.6953125e-05, 2.8906250e-05, 3.0859375e-05, 3.2812500e-05, 3.4765625e-05, 3.6718750e-05, 3.8671875e-05, 4.0625000e-05, 2.5000000e-05, 2.6562500e-05, 2.8125000e-05, 2.9687500e-05, 3.1250000e-05, 3.2812500e-05, 3.4375000e-05, 3.5937500e-05, 3.7500000e-05, 2.5000000e-05, 2.6171875e-05, 2.7343750e-05, 2.8515625e-05, 2.9687500e-05, 3.0859375e-05, 3.2031250e-05, 3.3203125e-05, 3.4375000e-05, 2.5000000e-05, 2.5781250e-05, 2.6562500e-05, 2.7343750e-05, 2.8125000e-05, 2.8906250e-05, 2.9687500e-05, 3.0468750e-05, 3.1250000e-05, 2.5000000e-05, 2.5390625e-05, 2.5781250e-05, 2.6171875e-05, 2.6562500e-05, 2.6953125e-05, 2.7343750e-05, 2.7734375e-05, 2.8125000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05, 2.5000000e-05]) - soil_p_pool_primary(cell_id)float640.001 0.0015 0.002 ... 0.001 0.001
- units :
- kg P m^-3
- description :
- Amount of phosphorus in a primary mineral form
- unit :
- kg{P} m^-3
array([0.001 , 0.0015 , 0.002 , 0.0025 , 0.003 , 0.0035 , 0.004 , 0.0045 , 0.005 , 0.001 , 0.0014375, 0.001875 , 0.0023125, 0.00275 , 0.0031875, 0.003625 , 0.0040625, 0.0045 , 0.001 , 0.001375 , 0.00175 , 0.002125 , 0.0025 , 0.002875 , 0.00325 , 0.003625 , 0.004 , 0.001 , 0.0013125, 0.001625 , 0.0019375, 0.00225 , 0.0025625, 0.002875 , 0.0031875, 0.0035 , 0.001 , 0.00125 , 0.0015 , 0.00175 , 0.002 , 0.00225 , 0.0025 , 0.00275 , 0.003 , 0.001 , 0.0011875, 0.001375 , 0.0015625, 0.00175 , 0.0019375, 0.002125 , 0.0023125, 0.0025 , 0.001 , 0.001125 , 0.00125 , 0.001375 , 0.0015 , 0.001625 , 0.00175 , 0.001875 , 0.002 , 0.001 , 0.0010625, 0.001125 , 0.0011875, 0.00125 , 0.0013125, 0.001375 , 0.0014375, 0.0015 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 ]) - soil_p_pool_secondary(cell_id)float640.005 0.01062 ... 0.005 0.005
- units :
- kg P m^-3
- description :
- Amount of inorganic phosphorus that is associated with secondary minerals
- unit :
- kg{P} m^-3
array([0.005 , 0.010625 , 0.01625 , 0.021875 , 0.0275 , 0.033125 , 0.03875 , 0.044375 , 0.05 , 0.005 , 0.00992188, 0.01484375, 0.01976562, 0.0246875 , 0.02960938, 0.03453125, 0.03945312, 0.044375 , 0.005 , 0.00921875, 0.0134375 , 0.01765625, 0.021875 , 0.02609375, 0.0303125 , 0.03453125, 0.03875 , 0.005 , 0.00851562, 0.01203125, 0.01554687, 0.0190625 , 0.02257813, 0.02609375, 0.02960938, 0.033125 , 0.005 , 0.0078125 , 0.010625 , 0.0134375 , 0.01625 , 0.0190625 , 0.021875 , 0.0246875 , 0.0275 , 0.005 , 0.00710938, 0.00921875, 0.01132812, 0.0134375 , 0.01554687, 0.01765625, 0.01976562, 0.021875 , 0.005 , 0.00640625, 0.0078125 , 0.00921875, 0.010625 , 0.01203125, 0.0134375 , 0.01484375, 0.01625 , 0.005 , 0.00570312, 0.00640625, 0.00710938, 0.0078125 , 0.00851562, 0.00921875, 0.00992188, 0.010625 , 0.005 , 0.005 , 0.005 , 0.005 , 0.005 , 0.005 , 0.005 , 0.005 , 0.005 ]) - subcanopy_seedbank_biomass(cell_id)float640.07 0.07 0.07 ... 0.07 0.07 0.07
- unit :
- kg C m^-2
- description :
- Carbon biomass of subcanopy seedbank.
array([0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07]) - subcanopy_vegetation_biomass(cell_id)float640.07 0.07 0.07 ... 0.07 0.07 0.07
- unit :
- kg C m^-2
- description :
- Carbon biomass of vegetation growing underneath the canopy.
array([0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07]) - wind_speed_ref(cell_id, time_index)float640.1885 0.06969 ... 0.1731 0.1343
- units :
- m s-1
- description :
- Wind speed at reference height (10m)
- unit :
- m s-1
array([[0.18852062, 0.06968677, 0.17029395, ..., 0.10203738, 0.04659857, 0.07501231], [0.13513061, 0.10404741, 0.18087363, ..., 0.05642059, 0.07821787, 0.09705558], [0.1318014 , 0.24203092, 0.20972227, ..., 0.15503302, 0.07394952, 0.1724549 ], ..., [0.19319498, 0.17270328, 0.17435737, ..., 0.12814455, 0.19391177, 0.24876822], [0.11994811, 0.23974676, 0.18293293, ..., 0.1209057 , 0.15771465, 0.03888232], [0.09124982, 0.20416301, 0.24250188, ..., 0.06340789, 0.17313909, 0.13428293]], shape=(81, 24))
extent = [
float(inputs["x"].min()),
float(inputs["x"].max()),
float(inputs["y"].min()),
float(inputs["y"].max()),
]
# Make two side by side plots
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 5))
# Elevation
im1 = ax1.imshow(inputs["elevation"].to_numpy().reshape((9, 9)), extent=extent)
ax1.set_title("Elevation (m)")
fig.colorbar(im1, ax=ax1, shrink=0.7)
# Initial soil carbon
im2 = ax2.imshow(inputs["pH"].to_numpy().reshape((9, 9)), extent=extent)
ax2.set_title("Soil pH (-)")
fig.colorbar(im2, ax=ax2, shrink=0.7)
plt.tight_layout()
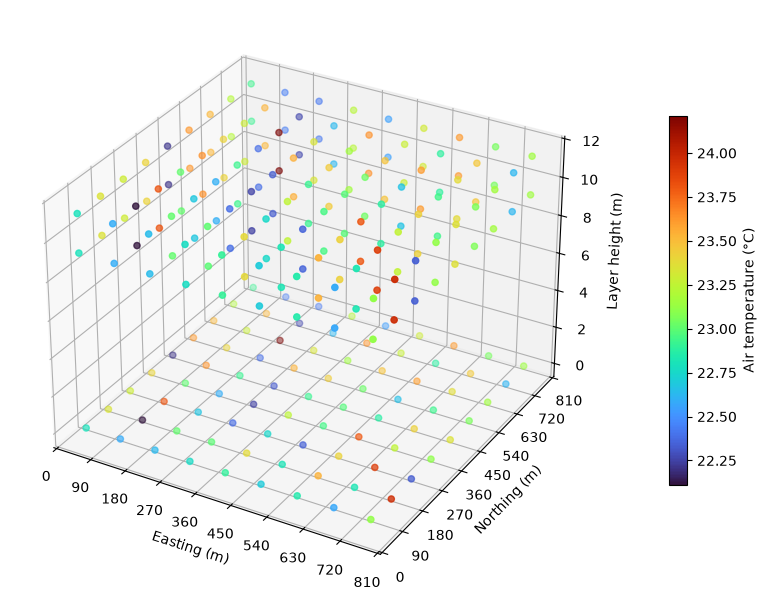
For some variables, it may be useful to visualise spatial structure in 3 dimensions. The obvious candidate is elevation.
# Extract the elevation data for a 3D plot
top = inputs["elevation"].to_numpy()
x = inputs["x"].to_numpy()
y = inputs["y"].to_numpy()
bottom = np.zeros_like(top)
width = depth = 90
# Make a 3D barplot of the elevation
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(projection="3d")
colors = plt.cm.turbo(top.flatten() / float(top.max()))
poly = ax.bar3d(x, y, bottom, width, depth, top, shade=True, color=colors)
ax.set_title("Elevation (m)")
cell_bounds = range(0, 811, 90)
ax.set_xticks(cell_bounds)
_ = ax.set_yticks(cell_bounds)

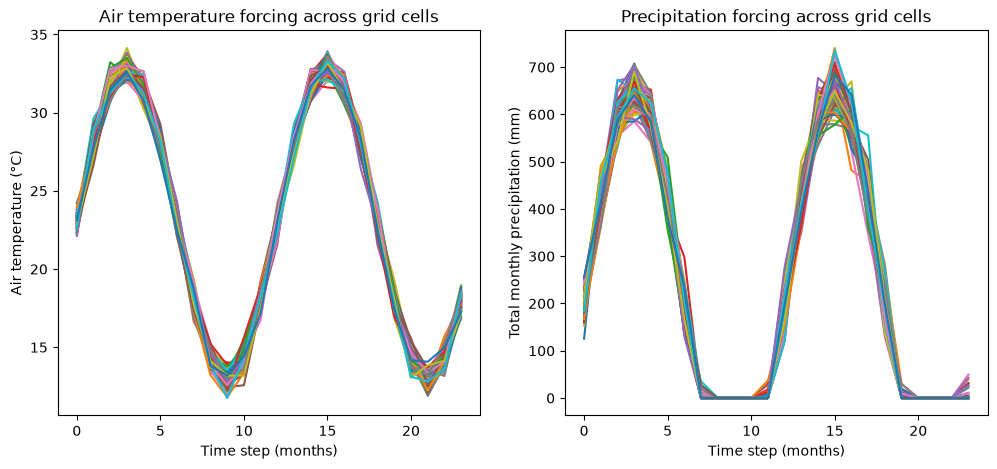
For other variables, such as air temperature and precipitation, the initial data also provides time series data at reference height that are used to force the simulation across the configured time period.
# Make two side by side plots
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
# Air temperature
ax1.plot(inputs["time_index"], inputs["air_temperature_ref"].T)
ax1.set_title("Air temperature forcing across grid cells")
ax1.set_ylabel("Air temperature (°C)")
ax1.set_xlabel("Time step (months)")
# Precipitation
ax2.plot(inputs["time_index"], inputs["precipitation"].T)
ax2.set_title("Precipitation forcing across grid cells")
ax2.set_ylabel("Total monthly precipitation (mm)")
_ = ax2.set_xlabel("Time step (months)")
Model initialisation#
The init group contains the state of model variables that are calculated when the
science models initialise. The science models are initialised in a specific order
so that each model has access to required initialisation data either in
the inputs or by the initialisation of other models.
init = xarray.load_dataset("ve_example/out/model_data.zarr", group="init")
init
<xarray.Dataset> Size: 374kB
Dimensions: (cell_id: 81, layers: 14, pft: 2,
element: 3, groundwater_layers: 2,
community_id: 81,
functional_group_id: 20,
time_index: 24)
Coordinates:
* cell_id (cell_id) int64 648B 0 1 2 ... 79 80
x (cell_id) int32 324B 0 90 ... 630 720
y (cell_id) int32 324B 720 720 ... 0 0
* layers (layers) int64 112B 0 1 2 ... 11 12 13
layer_roles (layers) <U7 392B 'above' ... 'subs...
* pft (pft) <U9 72B 'broadleaf' 'shrub'
* element (element) <U1 12B 'C' 'N' 'P'
* community_id (community_id) int64 648B 0 1 ... 80
* functional_group_id (functional_group_id) <U30 2kB 'car...
* time_index (time_index) int64 192B 0 1 ... 22 23
Dimensions without coordinates: groundwater_layers
Data variables: (12/69)
aerodynamic_resistance_canopy (cell_id) float64 648B 12.1 ... 12.1
aerodynamic_resistance_soil (layers, cell_id) float64 9kB 12.5 ...
air_temperature (layers, cell_id) float64 9kB 22.92...
arbuscular_mycorrhizal_n_supply (cell_id) float64 648B 0.002431 ......
arbuscular_mycorrhizal_p_supply (cell_id) float64 648B 3.213e-05 .....
atmospheric_co2 (layers, cell_id) float64 9kB 400.0...
... ...
total_animal_respiration (cell_id) float64 648B 0.0 0.0 ... 0.0
vapour_pressure (layers, cell_id) float64 9kB 2.351...
vapour_pressure_deficit (layers, cell_id) float64 9kB 0.439...
vapour_pressure_deficit_ref (cell_id, time_index) float64 16kB ...
vapour_pressure_ref (cell_id, time_index) float64 16kB ...
wind_speed (layers, cell_id) float64 9kB 0.188...- cell_id: 81
- layers: 14
- pft: 2
- element: 3
- groundwater_layers: 2
- community_id: 81
- functional_group_id: 20
- time_index: 24
- cell_id(cell_id)int640 1 2 3 4 5 6 ... 75 76 77 78 79 80
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80]) - x(cell_id)int320 90 180 270 ... 450 540 630 720
array([ 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720], dtype=int32) - y(cell_id)int32720 720 720 720 720 ... 0 0 0 0 0
array([720, 720, 720, 720, 720, 720, 720, 720, 720, 630, 630, 630, 630, 630, 630, 630, 630, 630, 540, 540, 540, 540, 540, 540, 540, 540, 540, 450, 450, 450, 450, 450, 450, 450, 450, 450, 360, 360, 360, 360, 360, 360, 360, 360, 360, 270, 270, 270, 270, 270, 270, 270, 270, 270, 180, 180, 180, 180, 180, 180, 180, 180, 180, 90, 90, 90, 90, 90, 90, 90, 90, 90, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32) - layers(layers)int640 1 2 3 4 5 6 7 8 9 10 11 12 13
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
- layer_roles(layers)<U7'above' 'canopy' ... 'subsoil'
array(['above', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'surface', 'topsoil', 'subsoil'], dtype='<U7') - pft(pft)<U9'broadleaf' 'shrub'
array(['broadleaf', 'shrub'], dtype='<U9')
- element(element)<U1'C' 'N' 'P'
array(['C', 'N', 'P'], dtype='<U1')
- community_id(community_id)int640 1 2 3 4 5 6 ... 75 76 77 78 79 80
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80]) - functional_group_id(functional_group_id)<U30'carnivorous_bird' ... 'thermoph...
array(['carnivorous_bird', 'herbivorous_bird', 'carnivorous_mammal', 'herbivorous_mammal', 'carnivorous_insect_iteroparous', 'herbivorous_insect_iteroparous', 'carnivorous_insect_semelparous', 'herbivorous_insect_semelparous', 'butterfly', 'caterpillar', 'frog', 'swallow', 'earthworm', 'dung_beetle', 'scavenging_mammal', 'detritivorous_insect', 'fungivorous_mammal', 'herbivorous_lizard', 'carnivorous_snake', 'thermophilic_lizard'], dtype='<U30') - time_index(time_index)int640 1 2 3 4 5 6 ... 18 19 20 21 22 23
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23])
- aerodynamic_resistance_canopy(cell_id)float6412.1 12.1 12.1 ... 12.1 12.1 12.1
- unit :
- s m-1
- description :
- Aerodynamic resistance canopy
array([12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1, 12.1]) - aerodynamic_resistance_soil(layers, cell_id)float6412.5 12.5 12.5 ... 12.5 12.5 12.5
- unit :
- s m-1
- description :
- Aerodynamic resistance soil
array([[12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5], [12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5], [12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5], ..., [12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5], [12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5], [12.5, 12.5, 12.5, ..., 12.5, 12.5, 12.5]], shape=(14, 81)) - air_temperature(layers, cell_id)float6422.92 22.43 22.42 ... nan nan nan
- unit :
- C
- description :
- Air temperature profile
array([[22.92320799, 22.43249701, 22.42066596, ..., 22.85555019, 22.5780398 , 23.11986464], [22.92259924, 22.43188826, 22.42005722, ..., 22.85494145, 22.57743106, 23.1192559 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [22.91647752, 22.42576654, 22.4139355 , ..., 22.84881972, 22.57130933, 23.11313418], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - arbuscular_mycorrhizal_n_supply(cell_id)float640.002431 0.005104 ... 0.002434
- unit :
- kg{N}
- description :
- Amount of nitrogen provided by arbuscular mycorrhizal fungi to their plant partners
array([0.00243094, 0.00510425, 0.00904618, 0.01470333, 0.02170194, 0.03127069, 0.04251428, 0.05527547, 0.07074101, 0.0024224 , 0.00475848, 0.00795469, 0.01227102, 0.01831536, 0.0250558 , 0.03331671, 0.04388129, 0.05484434, 0.00245208, 0.0043586 , 0.00710222, 0.01046902, 0.01470976, 0.0200304 , 0.02651838, 0.03349293, 0.04186568, 0.00244297, 0.00401267, 0.00592423, 0.00868106, 0.01177803, 0.01548335, 0.0196878 , 0.02511368, 0.03078795, 0.00238937, 0.00365929, 0.00515848, 0.00687481, 0.00910979, 0.01165385, 0.01460455, 0.01820368, 0.02194679, 0.00245114, 0.00328911, 0.00430975, 0.00548577, 0.00695327, 0.00858358, 0.01052633, 0.01245881, 0.01472264, 0.0024464 , 0.00303198, 0.00360758, 0.00429712, 0.00512068, 0.00595607, 0.00698882, 0.008127 , 0.00906688, 0.00245525, 0.0026559 , 0.00297491, 0.0033053 , 0.00368599, 0.0039536 , 0.00439668, 0.00468619, 0.00521757, 0.00240038, 0.00240994, 0.00240535, 0.00241505, 0.00241394, 0.00241408, 0.00241932, 0.00240973, 0.00243386]) - arbuscular_mycorrhizal_p_supply(cell_id)float643.213e-05 5.197e-05 ... 3.216e-05
- unit :
- kg{P}
- description :
- Amount of phosphorous provided by arbuscular mycorrhizal fungi to their plant partners
array([3.21270512e-05, 5.19707187e-05, 7.83035979e-05, 1.13733797e-04, 1.55080298e-04, 2.09964659e-04, 2.72552731e-04, 3.42464969e-04, 4.26227249e-04, 3.20187161e-05, 4.96806976e-05, 7.12630437e-05, 9.86508529e-05, 1.35506791e-04, 1.74551853e-04, 2.21359385e-04, 2.80083047e-04, 3.40204744e-04, 3.23954316e-05, 4.67763666e-05, 6.59889216e-05, 8.76607398e-05, 1.13778818e-04, 1.45490499e-04, 1.83058512e-04, 2.22377479e-04, 2.68971120e-04, 3.22797988e-05, 4.43241481e-05, 5.75608705e-05, 7.62848835e-05, 9.58313646e-05, 1.18422380e-04, 1.43267226e-04, 1.74908050e-04, 2.07127594e-04, 3.15996807e-05, 4.16975133e-05, 5.24896127e-05, 6.40190207e-05, 7.88105971e-05, 9.49080286e-05, 1.13042189e-04, 1.34764225e-04, 1.56634272e-04, 3.23835132e-05, 3.87653420e-05, 4.62808277e-05, 5.45387267e-05, 6.46983841e-05, 7.54921995e-05, 8.81016011e-05, 1.00024976e-04, 1.13869051e-04, 3.23233223e-05, 3.69979181e-05, 4.11375326e-05, 4.61527989e-05, 5.21278583e-05, 5.78498583e-05, 6.50063516e-05, 7.26926602e-05, 7.84685368e-05, 3.24356165e-05, 3.37131378e-05, 3.63324970e-05, 3.89470624e-05, 4.19867269e-05, 4.37056110e-05, 4.71628280e-05, 4.89690855e-05, 5.30553795e-05, 3.17394216e-05, 3.18606079e-05, 3.18024938e-05, 3.19255405e-05, 3.19113853e-05, 3.19131642e-05, 3.19796405e-05, 3.18580140e-05, 3.21641607e-05]) - atmospheric_co2(layers, cell_id)float64400.0 400.0 400.0 ... nan nan nan
- unit :
- ppm
- description :
- Atmospheric CO2 concentration profile
array([[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - atmospheric_pressure(layers, cell_id)float64100.1 101.6 100.9 ... nan nan nan
- unit :
- kPa
- description :
- Atmospheric pressure profile
array([[100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [ nan, nan, nan, ..., nan, nan, nan], ..., [100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - canopy_foliage_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of canopy foliage
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_foliage_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of canopy foliage consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_fruit_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- Average C, N, and P masses of each fruit per PFT in the canopy
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_fruit_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of canopy fruit consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_fruit_n(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of fruits of each PFT in the canopy
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_seed_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of each seed PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_seed_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of canopy seed consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_seeds_per_fruit(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of seeds per fruit in each PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - canopy_temperature(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- C
- description :
- Canopy temperature of individual layers
array([[ nan, nan, nan, ..., nan, nan, nan], [22.92259924, 22.43188826, 22.42005722, ..., 22.85494145, 22.57743106, 23.1192559 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [22.91647752, 22.42576654, 22.4139355 , ..., 22.84881972, 22.57130933, 23.11313418], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - condensation(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- mm
- description :
- Condensated water from supersaturation in the atmosphere
array([[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - density_air(layers, cell_id)float641.178 1.198 1.189 ... nan nan nan
- unit :
- kg m-3
- description :
- Temperature-dependent density of air
array([[1.17815899, 1.1976516 , 1.18946718, ..., 1.1942505 , 1.18462727, 1.18755795], [1.17815899, 1.1976516 , 1.18946718, ..., 1.1942505 , 1.18462727, 1.18755795], [ nan, nan, nan, ..., nan, nan, nan], ..., [1.17815899, 1.1976516 , 1.18946718, ..., 1.1942505 , 1.18462727, 1.18755795], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - dissolved_ammonium(cell_id)float645e-05 7.5e-05 ... 5e-05 5e-05
- units :
- kg N m^-3
- description :
- Concentration of dissolved ammonium in the topsoil layer
- unit :
- kg{N} m^-3
array([5.00000e-05, 7.50000e-05, 1.00000e-04, 1.25000e-04, 1.50000e-04, 1.75000e-04, 2.00000e-04, 2.25000e-04, 2.50000e-04, 5.00000e-05, 7.18750e-05, 9.37500e-05, 1.15625e-04, 1.37500e-04, 1.59375e-04, 1.81250e-04, 2.03125e-04, 2.25000e-04, 5.00000e-05, 6.87500e-05, 8.75000e-05, 1.06250e-04, 1.25000e-04, 1.43750e-04, 1.62500e-04, 1.81250e-04, 2.00000e-04, 5.00000e-05, 6.56250e-05, 8.12500e-05, 9.68750e-05, 1.12500e-04, 1.28125e-04, 1.43750e-04, 1.59375e-04, 1.75000e-04, 5.00000e-05, 6.25000e-05, 7.50000e-05, 8.75000e-05, 1.00000e-04, 1.12500e-04, 1.25000e-04, 1.37500e-04, 1.50000e-04, 5.00000e-05, 5.93750e-05, 6.87500e-05, 7.81250e-05, 8.75000e-05, 9.68750e-05, 1.06250e-04, 1.15625e-04, 1.25000e-04, 5.00000e-05, 5.62500e-05, 6.25000e-05, 6.87500e-05, 7.50000e-05, 8.12500e-05, 8.75000e-05, 9.37500e-05, 1.00000e-04, 5.00000e-05, 5.31250e-05, 5.62500e-05, 5.93750e-05, 6.25000e-05, 6.56250e-05, 6.87500e-05, 7.18750e-05, 7.50000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05, 5.00000e-05]) - dissolved_nitrate(cell_id)float640.001 0.0015 0.002 ... 0.001 0.001
- units :
- kg N m^-3
- description :
- Concentration of dissolved nitrate in the topsoil layer
- unit :
- kg{N} m^-3
array([0.001 , 0.0015 , 0.002 , 0.0025 , 0.003 , 0.0035 , 0.004 , 0.0045 , 0.005 , 0.001 , 0.0014375, 0.001875 , 0.0023125, 0.00275 , 0.0031875, 0.003625 , 0.0040625, 0.0045 , 0.001 , 0.001375 , 0.00175 , 0.002125 , 0.0025 , 0.002875 , 0.00325 , 0.003625 , 0.004 , 0.001 , 0.0013125, 0.001625 , 0.0019375, 0.00225 , 0.0025625, 0.002875 , 0.0031875, 0.0035 , 0.001 , 0.00125 , 0.0015 , 0.00175 , 0.002 , 0.00225 , 0.0025 , 0.00275 , 0.003 , 0.001 , 0.0011875, 0.001375 , 0.0015625, 0.00175 , 0.0019375, 0.002125 , 0.0023125, 0.0025 , 0.001 , 0.001125 , 0.00125 , 0.001375 , 0.0015 , 0.001625 , 0.00175 , 0.001875 , 0.002 , 0.001 , 0.0010625, 0.001125 , 0.0011875, 0.00125 , 0.0013125, 0.001375 , 0.0014375, 0.0015 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 , 0.001 ]) - dissolved_phosphorus(cell_id)float641.25e-07 1.406e-07 ... 1.25e-07
- units :
- kg P m^-3
- description :
- Concentration of dissolved labile inorganic phosphorus in the topsoil layer
- unit :
- kg{P} m^-3
array([1.25000000e-07, 1.40625000e-07, 1.56250000e-07, 1.71875000e-07, 1.87500000e-07, 2.03125000e-07, 2.18750000e-07, 2.34375000e-07, 2.50000000e-07, 1.25000000e-07, 1.38671875e-07, 1.52343750e-07, 1.66015625e-07, 1.79687500e-07, 1.93359375e-07, 2.07031250e-07, 2.20703125e-07, 2.34375000e-07, 1.25000000e-07, 1.36718750e-07, 1.48437500e-07, 1.60156250e-07, 1.71875000e-07, 1.83593750e-07, 1.95312500e-07, 2.07031250e-07, 2.18750000e-07, 1.25000000e-07, 1.34765625e-07, 1.44531250e-07, 1.54296875e-07, 1.64062500e-07, 1.73828125e-07, 1.83593750e-07, 1.93359375e-07, 2.03125000e-07, 1.25000000e-07, 1.32812500e-07, 1.40625000e-07, 1.48437500e-07, 1.56250000e-07, 1.64062500e-07, 1.71875000e-07, 1.79687500e-07, 1.87500000e-07, 1.25000000e-07, 1.30859375e-07, 1.36718750e-07, 1.42578125e-07, 1.48437500e-07, 1.54296875e-07, 1.60156250e-07, 1.66015625e-07, 1.71875000e-07, 1.25000000e-07, 1.28906250e-07, 1.32812500e-07, 1.36718750e-07, 1.40625000e-07, 1.44531250e-07, 1.48437500e-07, 1.52343750e-07, 1.56250000e-07, 1.25000000e-07, 1.26953125e-07, 1.28906250e-07, 1.30859375e-07, 1.32812500e-07, 1.34765625e-07, 1.36718750e-07, 1.38671875e-07, 1.40625000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07, 1.25000000e-07]) - diurnal_temperature_range(layers, cell_id)float645.0 5.0 5.0 5.0 ... nan nan nan nan
- unit :
- C
- description :
- Diurnal air temperature range
array([[ 5., 5., 5., ..., 5., 5., 5.], [ 5., 5., 5., ..., 5., 5., 5.], [nan, nan, nan, ..., nan, nan, nan], ..., [ 5., 5., 5., ..., 5., 5., 5.], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - ectomycorrhizal_n_supply(cell_id)float640.002431 0.005104 ... 0.002434
- unit :
- kg{N}
- description :
- Amount of nitrogen provided by ectomycorrhizal fungi to their plant partners
array([0.00243094, 0.00510425, 0.00904618, 0.01470333, 0.02170194, 0.03127069, 0.04251428, 0.05527547, 0.07074101, 0.0024224 , 0.00475848, 0.00795469, 0.01227102, 0.01831536, 0.0250558 , 0.03331671, 0.04388129, 0.05484434, 0.00245208, 0.0043586 , 0.00710222, 0.01046902, 0.01470976, 0.0200304 , 0.02651838, 0.03349293, 0.04186568, 0.00244297, 0.00401267, 0.00592423, 0.00868106, 0.01177803, 0.01548335, 0.0196878 , 0.02511368, 0.03078795, 0.00238937, 0.00365929, 0.00515848, 0.00687481, 0.00910979, 0.01165385, 0.01460455, 0.01820368, 0.02194679, 0.00245114, 0.00328911, 0.00430975, 0.00548577, 0.00695327, 0.00858358, 0.01052633, 0.01245881, 0.01472264, 0.0024464 , 0.00303198, 0.00360758, 0.00429712, 0.00512068, 0.00595607, 0.00698882, 0.008127 , 0.00906688, 0.00245525, 0.0026559 , 0.00297491, 0.0033053 , 0.00368599, 0.0039536 , 0.00439668, 0.00468619, 0.00521757, 0.00240038, 0.00240994, 0.00240535, 0.00241505, 0.00241394, 0.00241408, 0.00241932, 0.00240973, 0.00243386]) - ectomycorrhizal_p_supply(cell_id)float643.213e-05 5.197e-05 ... 3.216e-05
- unit :
- kg{P}
- description :
- Amount of phosphorous provided by ectomycorrhizal fungi to their plant partners
array([3.21270512e-05, 5.19707187e-05, 7.83035979e-05, 1.13733797e-04, 1.55080298e-04, 2.09964659e-04, 2.72552731e-04, 3.42464969e-04, 4.26227249e-04, 3.20187161e-05, 4.96806976e-05, 7.12630437e-05, 9.86508529e-05, 1.35506791e-04, 1.74551853e-04, 2.21359385e-04, 2.80083047e-04, 3.40204744e-04, 3.23954316e-05, 4.67763666e-05, 6.59889216e-05, 8.76607398e-05, 1.13778818e-04, 1.45490499e-04, 1.83058512e-04, 2.22377479e-04, 2.68971120e-04, 3.22797988e-05, 4.43241481e-05, 5.75608705e-05, 7.62848835e-05, 9.58313646e-05, 1.18422380e-04, 1.43267226e-04, 1.74908050e-04, 2.07127594e-04, 3.15996807e-05, 4.16975133e-05, 5.24896127e-05, 6.40190207e-05, 7.88105971e-05, 9.49080286e-05, 1.13042189e-04, 1.34764225e-04, 1.56634272e-04, 3.23835132e-05, 3.87653420e-05, 4.62808277e-05, 5.45387267e-05, 6.46983841e-05, 7.54921995e-05, 8.81016011e-05, 1.00024976e-04, 1.13869051e-04, 3.23233223e-05, 3.69979181e-05, 4.11375326e-05, 4.61527989e-05, 5.21278583e-05, 5.78498583e-05, 6.50063516e-05, 7.26926602e-05, 7.84685368e-05, 3.24356165e-05, 3.37131378e-05, 3.63324970e-05, 3.89470624e-05, 4.19867269e-05, 4.37056110e-05, 4.71628280e-05, 4.89690855e-05, 5.30553795e-05, 3.17394216e-05, 3.18606079e-05, 3.18024938e-05, 3.19255405e-05, 3.19113853e-05, 3.19131642e-05, 3.19796405e-05, 3.18580140e-05, 3.21641607e-05]) - fallen_fruit_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- Average C, N, and P masses of each fruit per PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - fallen_fruit_n(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of fallen fruits per PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - fallen_seeds_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- Average C, N, and P masses of each seed in a PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - fallen_seeds_per_fruit(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of seeds per fruit per PFT
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - foliage_turnover_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for foliage turnover in a given timestep
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - foliage_turnover_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of foliage turnover consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - fruit_turnover_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C
- description :
- Biomasses of plant fruit tissue turnover
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - fruit_turnover_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of fruit turnover consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - groundwater_storage(groundwater_layers, cell_id)float64450.0 450.0 450.0 ... 450.0 450.0
- unit :
- mm
- description :
- Groundwater Storage
array([[450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450.], [450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450., 450.]]) - latent_heat_vapourisation(layers, cell_id)float642.447e+03 2.448e+03 ... nan nan
- unit :
- kJ kg-1
- description :
- Latent heat of vapourisation
array([[2446.8507628 , 2447.90195104, 2447.92734666, ..., 2446.99545022, 2447.58973847, 2446.43065691], [2446.8507628 , 2447.90195104, 2447.92734666, ..., 2446.99545022, 2447.58973847, 2446.43065691], [ nan, nan, nan, ..., nan, nan, nan], ..., [2446.8507628 , 2447.90195104, 2447.92734666, ..., 2446.99545022, 2447.58973847, 2446.43065691], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - layer_fapar(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- -
- description :
- The fraction of absorbed photosynthetically active radiation (f_APAR) in each model layer.
array([[ nan, nan, nan, ..., nan, nan, nan], [0.00136884, 0.00136884, 0.00136884, ..., 0.00136884, 0.00136884, 0.00136884], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.38684335, 0.38684335, 0.38684335, ..., 0.38684335, 0.38684335, 0.38684335], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - layer_heights(layers, cell_id)float6411.31 11.31 11.31 ... -1.0 -1.0
- unit :
- m
- description :
- Heights of model layers
array([[11.30685131, 11.30685131, 11.30685131, ..., 11.30685131, 11.30685131, 11.30685131], [ 9.30685131, 9.30685131, 9.30685131, ..., 9.30685131, 9.30685131, 9.30685131], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 0.1 , 0.1 , 0.1 , ..., 0.1 , 0.1 , 0.1 ], [-0.25 , -0.25 , -0.25 , ..., -0.25 , -0.25 , -0.25 ], [-1. , -1. , -1. , ..., -1. , -1. , -1. ]], shape=(14, 81)) - layer_leaf_mass(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- kg
- description :
- The leaf mass within each canopy layer.
array([[ nan, nan, nan, ..., nan, nan, nan], [2.40221643, 2.40221643, 2.40221643, ..., 2.40221643, 2.40221643, 2.40221643], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - leaf_area_index(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- m m-1
- description :
- Leaf area index
array([[ nan, nan, nan, ..., nan, nan, nan], [0.00415198, 0.00415198, 0.00415198, ..., 0.00415198, 0.00415198, 0.00415198], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.98 , 0.98 , 0.98 , ..., 0.98 , 0.98 , 0.98 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - litter_consumed_above_metabolic_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of above-ground metabolic litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - litter_consumed_above_structural_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of above-ground structural litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - litter_consumed_below_metabolic_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of below-ground metabolic litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - litter_consumed_below_structural_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of below-ground structural litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - litter_consumed_woody_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of woody litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - matric_potential(layers, cell_id)float64nan nan nan ... -49.67 -49.67
- unit :
- kPa
- description :
- Matric potential
array([[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [-49.67361284, -49.67361284, -49.67361284, ..., -49.67361284, -49.67361284, -49.67361284], [-49.67361284, -49.67361284, -49.67361284, ..., -49.67361284, -49.67361284, -49.67361284]], shape=(14, 81)) - net_radiation(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- W m-2
- description :
- Net radiation
array([[ nan, nan, nan, ..., nan, nan, nan], [ 2.7770893 , 2.77836147, 2.77839113, ..., 2.77726963, 2.77799274, 2.77655598], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 789.14511551, 789.14638665, 789.14641629, ..., 789.14529571, 789.14601822, 789.14458262], [1248.03095278, 1248.0319953 , 1248.03287546, ..., 1248.03183429, 1248.03196108, 1248.03122149], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - population_densities(community_id, functional_group_id)float640.02691 0.02123 ... 0.001358
- unit :
- individual m-2
- description :
- Density of animal populations.
array([[0.02691358, 0.02123457, 0.1 , ..., 0.02135802, 0.02691358, 0.00271605], [0.03777778, 0.02851852, 0.1 , ..., 0.0282716 , 0.03777778, 0.00296296], [0.04333333, 0.02839506, 0.1 , ..., 0.0282716 , 0.04320988, 0.00283951], ..., [0.02716049, 0.02814815, 0.1 , ..., 0.0282716 , 0.02703704, 0.00148148], [0.02716049, 0.0282716 , 0.1 , ..., 0.0282716 , 0.02716049, 0.00135802], [0.0217284 , 0.02123457, 0.1 , ..., 0.02123457, 0.0217284 , 0.00135802]], shape=(81, 20)) - production_of_fungal_fruiting_bodies(cell_id)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C m^-2 day^-1
- description :
- Rate at which fungal fruiting bodies are produced by soil fungi
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - relative_humidity(layers, cell_id)float6484.26 84.32 87.01 ... nan nan nan
- unit :
- %
- description :
- Relative humidity profile
array([[84.26389887, 84.31929038, 87.00965838, ..., 83.35697745, 83.72106275, 84.49945442], [84.27893374, 84.33432525, 87.02469325, ..., 83.37201232, 83.73609762, 84.51448929], [ nan, nan, nan, ..., nan, nan, nan], ..., [84.28637422, 84.34176573, 87.03213373, ..., 83.3794528 , 83.7435381 , 84.52192977], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - root_turnover_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for root turnover in a given timestep
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - seed_turnover_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C
- description :
- Biomasses of plant seed tissue turnover
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - seed_turnover_cnp_consumed(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of seed turnover consumed by animals
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - shortwave_absorption(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- W m-2
- description :
- Shortwave radiation absorbed by individual canopy layers
array([[ nan, nan, nan, ..., nan, nan, nan], [ 2.7924317 , 2.7924317 , 2.7924317 , ..., 2.7924317 , 2.7924317 , 2.7924317 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 789.16044153, 789.16044153, 789.16044153, ..., 789.16044153, 789.16044153, 789.16044153], [1248.04712678, 1248.04712678, 1248.04712678, ..., 1248.04712678, 1248.04712678, 1248.04712678], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - soil_moisture(layers, cell_id)float64nan nan nan ... 375.0 375.0 375.0
- unit :
- mm
- description :
- Soil moisture
array([[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [125., 125., 125., ..., 125., 125., 125.], [375., 375., 375., ..., 375., 375., 375.]], shape=(14, 81)) - soil_temperature(layers, cell_id)float64nan nan nan ... 23.3 23.46 23.49
- unit :
- C
- description :
- Soil temperature profile
array([[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [23.40833389, 23.02165238, 22.67931372, ..., 23.08264969, 23.03465506, 23.31049758], [23.8579326 , 23.56634292, 22.92189207, ..., 23.29639025, 23.45819261, 23.49090457]], shape=(14, 81)) - specific_heat_air(layers, cell_id)float641.02 1.019 1.019 ... nan nan nan
- unit :
- J kg-1 K-1
- description :
- Specific heat of air
array([[1.01950307, 1.01911712, 1.01910809, ..., 1.01944853, 1.01922928, 1.01966403], [1.01950307, 1.01911712, 1.01910809, ..., 1.01944853, 1.01922928, 1.01966403], [ nan, nan, nan, ..., nan, nan, nan], ..., [1.01950307, 1.01911712, 1.01910809, ..., 1.01944853, 1.01922928, 1.01966403], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - stem_turnover_cnp(cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for stem turnover in a given timestep
array([[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ... [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]) - stomatal_conductance(layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- mol m-2 s-1
- description :
- Stomatal conductance
array([[ nan, nan, nan, ..., nan, nan, nan], [1000., 1000., 1000., ..., 1000., 1000., 1000.], [ nan, nan, nan, ..., nan, nan, nan], ..., [1000., 1000., 1000., ..., 1000., 1000., 1000.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - subcanopy_seedbank_cnp(cell_id, element)float640.07 0.0035 ... 0.0035 0.0014
- unit :
- kg
- description :
- C, N, and P masses for the subcanopy seedbank CNP
array([[0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], ... [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014]]) - subcanopy_seedbank_cnp_consumed(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C m^-2
- description :
- C, N, and P masses of subcanopy seedbank consumed by animals.
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - subcanopy_seedbank_litter_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for the ground seedbank
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - subcanopy_vegetation_cnp(cell_id, element)float640.07 0.0035 ... 0.0035 0.0014
- unit :
- kg
- description :
- C, N, and P masses for subcanopy vegetation
array([[0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], ... [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014], [0.07 , 0.0035, 0.0014]]) - subcanopy_vegetation_cnp_consumed(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C m^-2
- description :
- C, N, and P masses of subcanopy vegetation consumed by animals.
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - subcanopy_vegetation_litter_cnp(cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for subcanopy turnover in a given timestep
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ... [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) - total_animal_respiration(cell_id)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- ppm
- description :
- Animal respiration aggregated over all functional types
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - vapour_pressure(layers, cell_id)float642.351 2.283 2.354 ... nan nan nan
- unit :
- kPa
- description :
- Vapour pressure profile
array([[2.35055807, 2.28314896, 2.35430446, ..., 2.31575474, 2.28707109, 2.38533085], [2.35089085, 2.28347162, 2.35462419, ..., 2.31608705, 2.28739732, 2.3856675 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [2.35022744, 2.28282397, 2.35394986, ..., 2.31543524, 2.28675092, 2.38499499], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - vapour_pressure_deficit(layers, cell_id)float640.439 0.4246 0.3515 ... nan nan nan
- unit :
- kPa
- description :
- Vapour pressure deficit profile
array([[0.43896164, 0.42459318, 0.35149223, ..., 0.46236271, 0.44470394, 0.43756412], [0.43896164, 0.42459318, 0.35149223, ..., 0.46236271, 0.44470394, 0.43756412], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.001 , 0.001 , 0.001 , ..., 0.001 , 0.001 , 0.001 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81)) - vapour_pressure_deficit_ref(cell_id, time_index)float640.439 0.2807 0.0 ... 0.4862 0.4231
- units :
- %
- description :
- Vapour pressure deficit at reference height (2m)
- unit :
- kPa
array([[0.43896164, 0.28065762, 0. , ..., 0.47524864, 0.4894881 , 0.44571947], [0.42459318, 0.23948423, 0.28160047, ..., 0.42046734, 0.51578001, 0.46495103], [0.35149223, 0.31459818, 0.08983537, ..., 0.46372125, 0.44641043, 0.43634408], ..., [0.46236271, 0.34376235, 0.26394872, ..., 0.47047843, 0.42762059, 0.49105261], [0.44470394, 0.29657363, 0.16228786, ..., 0.46605272, 0.46164066, 0.46351671], [0.43756412, 0.3721686 , 0.09188263, ..., 0.48217933, 0.48623729, 0.42311368]], shape=(81, 24)) - vapour_pressure_ref(cell_id, time_index)float642.351 3.347 4.672 ... 1.213 1.541
- units :
- %
- description :
- Vapour pressure at reference height (2m)
- unit :
- kPa
array([[2.35055807, 3.34727184, 4.67188847, ..., 0.99169115, 1.17731522, 1.6099304 ], [2.28314896, 3.43927708, 4.48085921, ..., 0.98249501, 1.12666116, 1.63596784], [2.35430446, 3.55890469, 4.58354408, ..., 1.00268609, 1.12100935, 1.69053503], ..., [2.31575474, 3.26901852, 4.54574857, ..., 1.10938576, 1.18198716, 1.45945881], [2.28707109, 3.69531796, 4.38740334, ..., 1.01110372, 1.09368994, 1.64934962], [2.38533085, 3.3363309 , 4.50694715, ..., 1.12084365, 1.21284094, 1.54104437]], shape=(81, 24)) - wind_speed(layers, cell_id)float640.1885 0.1351 0.1318 ... nan nan
- unit :
- m s-1
- description :
- Wind profile within and below canopy
array([[0.18852062, 0.13513061, 0.1318014 , ..., 0.19319498, 0.11994811, 0.09124982], [0.18848061, 0.1350906 , 0.13176139, ..., 0.19315496, 0.1199081 , 0.09120981], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.18754879, 0.13415878, 0.13082957, ..., 0.19222314, 0.11897628, 0.09027798], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], shape=(14, 81))
A good example is the layer heights within the simulation - this is calculated from the configuration of ground layers and the heights of trees in the initial plant community data and provides the vertical structure for the calculation of initial abiotic conditions and other model components
# Loop over vertical layers
for layer in init["layers"]:
# Get the data for the layer
layer_data = init["layer_heights"].sel(layers=layer)
if not np.all(np.isnan(layer_data)):
# Plot layers that contain some canopy or other data.
plt.plot(
init["cell_id"],
init["layer_heights"].sel(layers=layer),
label=init["layer_roles"].sel(layers=layer).data,
)
plt.xlabel("Cell ID")
plt.ylabel("Layer height (metres)")
plt.legend()
Model outputs#
The main output of interest is the outputs group, which contains
variables describing the change in the models through the simulation process.
outputs = xarray.load_dataset("ve_example/out/model_data.zarr", group="outputs")
outputs
<xarray.Dataset> Size: 8MB
Dimensions: (time_index: 24, cell_id: 81,
layers: 14, element: 3, pft: 2,
groundwater_layers: 2)
Coordinates:
* time_index (time_index) int64 192B 0 1 ... 23
* cell_id (cell_id) int64 648B 0 1 ... 79 80
x (cell_id) int32 324B 0 90 ... 720
y (cell_id) int32 324B 720 720 ... 0
* layers (layers) int64 112B 0 1 ... 12 13
layer_roles (layers) <U7 392B 'above' ... '...
* element (element) <U1 12B 'C' 'N' 'P'
* pft (pft) <U9 72B 'broadleaf' 'shrub'
Dimensions without coordinates: groundwater_layers
Data variables: (12/126)
aerodynamic_resistance_soil (time_index, cell_id) float64 16kB ...
air_temperature (time_index, layers, cell_id) float64 218kB ...
animal_arbuscular_mycorrhiza_consumption (time_index, cell_id) float64 16kB ...
animal_bacteria_consumption (time_index, cell_id) float64 16kB ...
animal_ectomycorrhiza_consumption (time_index, cell_id) float64 16kB ...
animal_pom_consumption_cnp (time_index, cell_id, element) float64 47kB ...
... ...
total_runoff (time_index, cell_id) float64 16kB ...
transpiration (time_index, layers, cell_id) float64 218kB ...
vapour_pressure (time_index, layers, cell_id) float64 218kB ...
vapour_pressure_deficit (time_index, layers, cell_id) float64 218kB ...
vertical_flow (time_index, layers, cell_id) float64 218kB ...
wind_speed (time_index, layers, cell_id) float64 218kB ...- time_index: 24
- cell_id: 81
- layers: 14
- element: 3
- pft: 2
- groundwater_layers: 2
- time_index(time_index)int640 1 2 3 4 5 6 ... 18 19 20 21 22 23
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]) - cell_id(cell_id)int640 1 2 3 4 5 6 ... 75 76 77 78 79 80
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80]) - x(cell_id)int320 90 180 270 ... 450 540 630 720
array([ 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720, 0, 90, 180, 270, 360, 450, 540, 630, 720], dtype=int32) - y(cell_id)int32720 720 720 720 720 ... 0 0 0 0 0
array([720, 720, 720, 720, 720, 720, 720, 720, 720, 630, 630, 630, 630, 630, 630, 630, 630, 630, 540, 540, 540, 540, 540, 540, 540, 540, 540, 450, 450, 450, 450, 450, 450, 450, 450, 450, 360, 360, 360, 360, 360, 360, 360, 360, 360, 270, 270, 270, 270, 270, 270, 270, 270, 270, 180, 180, 180, 180, 180, 180, 180, 180, 180, 90, 90, 90, 90, 90, 90, 90, 90, 90, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32) - layers(layers)int640 1 2 3 4 5 6 7 8 9 10 11 12 13
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
- layer_roles(layers)<U7'above' 'canopy' ... 'subsoil'
array(['above', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'canopy', 'surface', 'topsoil', 'subsoil'], dtype='<U7') - element(element)<U1'C' 'N' 'P'
array(['C', 'N', 'P'], dtype='<U1')
- pft(pft)<U9'broadleaf' 'shrub'
array(['broadleaf', 'shrub'], dtype='<U9')
- aerodynamic_resistance_soil(time_index, cell_id)float6426.66 37.27 38.22 ... 316.4 46.1
- unit :
- s m-1
- description :
- Aerodynamic resistance soil
array([[ 26.65973012, 37.26927217, 38.21766063, ..., 26.01143657, 42.02518475, 55.3844886 ], [ 72.76444847, 48.44818636, 20.74182429, ..., 29.1152378 , 20.94023306, 24.60740658], [ 29.58574589, 27.81878443, 23.98983012, ..., 28.89092245, 27.50312524, 20.72902783], ..., [ 58.67685969, 134.53130264, 37.68781901, ..., 44.66665867, 49.14865494, 118.61121781], [177.54851704, 88.22319301, 100.77064688, ..., 28.43256924, 36.65076897, 33.40983714], [ 91.62001824, 67.92431934, 34.26861193, ..., 21.86299267, 316.42895975, 46.10338093]], shape=(24, 81)) - air_temperature(time_index, layers, cell_id)float6422.92 22.43 22.42 ... nan nan nan
- unit :
- C
- description :
- Air temperature profile
array([[[22.92320799, 22.43249701, 22.42066596, ..., 22.85555019, 22.5780398 , 23.11986464], [22.92259924, 22.43188826, 22.42005722, ..., 22.85494145, 22.57743106, 23.1192559 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [22.91647752, 22.42576654, 22.4139355 , ..., 22.84881972, 22.57130933, 23.11313418], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[27.33726005, 27.57505607, 28.46029346, ..., 27.26583056, 28.97963397, 27.71284634], [27.33665127, 27.57452717, 28.45968456, ..., 27.26522177, 28.97902514, 27.7122374 ], [ nan, nan, nan, ..., nan, nan, nan], ... [14.54639575, 14.29595032, 13.55396554, ..., 14.00855784, 13.45653889, 14.80816838], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[17.97308933, 18.32018899, 18.51628715, ..., 17.14029154, 18.41070032, 17.25058122], [17.96702876, 18.31322311, 18.50839709, ..., 17.13432767, 18.40384338, 17.24291538], [ nan, nan, nan, ..., nan, nan, nan], ..., [17.82664793, 18.15223972, 18.32610044, ..., 16.99650589, 18.24535167, 17.06551853], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - animal_arbuscular_mycorrhiza_consumption(time_index, cell_id)float640.0 0.0 -9.499e-21 ... 0.0 0.0 0.0
- unit :
- kg C m^-3 day^-1
- description :
- Rate at which arbuscular mycorrhizal soil fungi are being consumed by animals
array([[ 0.00000000e+00, 0.00000000e+00, -9.49882807e-21, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [-9.33668365e-21, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], shape=(24, 81)) - animal_bacteria_consumption(time_index, cell_id)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg C m^-3 day^-1
- description :
- Rate at which soil bacteria are being consumed by animals
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]], shape=(24, 81)) - animal_ectomycorrhiza_consumption(time_index, cell_id)float640.0 0.0 -9.499e-21 ... 0.0 0.0 0.0
- unit :
- kg C m^-3 day^-1
- description :
- Rate at which ectomycorrhizal soil fungi are being consumed by animals
array([[ 0.00000000e+00, 0.00000000e+00, -9.49882807e-21, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [-9.33391555e-21, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], shape=(24, 81)) - animal_pom_consumption_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg m^-3 day^-1
- description :
- Rate at which carbon, nitrogen and phosphorus components of soil particulate organic matter are consumed by animals
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - animal_saprotrophic_fungi_consumption(time_index, cell_id)float640.0 0.0 -9.499e-21 ... 0.0 0.0 0.0
- unit :
- kg C m^-3 day^-1
- description :
- Rate at which saprotrophic soil fungi are being consumed by animals
array([[ 0.00000000e+00, 0.00000000e+00, -9.49882807e-21, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [-9.82588500e-21, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], shape=(24, 81)) - arbuscular_mycorrhizal_n_supply(time_index, cell_id)float649.344e-06 8.26e-06 ... 0.0003727
- unit :
- kg{N}
- description :
- Amount of nitrogen provided by arbuscular mycorrhizal fungi to their plant partners
array([[9.34427048e-06, 8.26038552e-06, 9.63783919e-06, ..., 9.36511215e-06, 9.44897065e-06, 9.31582786e-06], [1.12742935e-05, 9.84647037e-06, 1.06859747e-05, ..., 1.11325205e-05, 9.11991776e-06, 1.09243413e-05], [1.28043278e-05, 1.02563717e-05, 1.22044422e-05, ..., 1.00401427e-05, 1.07973725e-05, 1.23276535e-05], ..., [2.48762996e-04, 2.93045643e-04, 3.30487714e-04, ..., 2.43016007e-04, 2.88818122e-04, 3.14543468e-04], [2.73049694e-04, 3.12382473e-04, 3.60287859e-04, ..., 2.71370597e-04, 3.11465941e-04, 3.46112723e-04], [2.89529631e-04, 3.31991108e-04, 3.72545161e-04, ..., 2.88304890e-04, 3.26622110e-04, 3.72652528e-04]], shape=(24, 81)) - arbuscular_mycorrhizal_p_supply(time_index, cell_id)float641.378e-06 1.218e-06 ... 5.495e-05
- unit :
- kg{P}
- description :
- Amount of phosphorous provided by arbuscular mycorrhizal fungi to their plant partners
array([[1.37788395e-06, 1.21805685e-06, 1.42117290e-06, ..., 1.38095722e-06, 1.39332279e-06, 1.37368987e-06], [1.66248057e-06, 1.45193716e-06, 1.57572847e-06, ..., 1.64157505e-06, 1.34480143e-06, 1.61087745e-06], [1.88809579e-06, 1.51238023e-06, 1.79963809e-06, ..., 1.48049561e-06, 1.59215493e-06, 1.81780653e-06], ..., [3.66820011e-05, 4.32118152e-05, 4.87329341e-05, ..., 3.58345638e-05, 4.25884349e-05, 4.63818334e-05], [4.02632600e-05, 4.60631782e-05, 5.31271927e-05, ..., 4.00156643e-05, 4.59280286e-05, 5.10369609e-05], [4.26933524e-05, 4.89546210e-05, 5.49346255e-05, ..., 4.25127550e-05, 4.81629213e-05, 5.49504575e-05]], shape=(24, 81)) - atmospheric_co2(time_index, layers, cell_id)float64400.0 400.0 400.0 ... nan nan nan
- unit :
- ppm
- description :
- Atmospheric CO2 concentration profile
array([[[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., ... ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[400., 400., 400., ..., 400., 400., 400.], [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], ..., [400., 400., 400., ..., 400., 400., 400.], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - atmospheric_pressure(time_index, layers, cell_id)float64100.1 101.6 100.9 ... nan nan nan
- unit :
- kPa
- description :
- Atmospheric pressure profile
array([[[100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [ nan, nan, nan, ..., nan, nan, nan], ..., [100.12915774, 101.61709194, 100.91862927, ..., 101.47354612, 100.56150941, 100.99499278], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[100.70696051, 100.96351614, 100.64823838, ..., 101.59024389, 101.36044394, 101.66478406], [100.70696051, 100.96351614, 100.64823838, ..., 101.59024389, 101.36044394, 101.66478406], [ nan, nan, nan, ..., nan, nan, nan], ... [100.22877698, 99.81272126, 100.35779359, ..., 99.79493477, 100.12958153, 100.1880621 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ 99.82598774, 100.08742535, 100.38828998, ..., 101.3809399 , 100.42776646, 100.90024182], [ 99.82598774, 100.08742535, 100.38828998, ..., 101.3809399 , 100.42776646, 100.90024182], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 99.82598774, 100.08742535, 100.38828998, ..., 101.3809399 , 100.42776646, 100.90024182], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - baseflow(time_index, cell_id)float64714.5 714.5 ... 1.14e+03 1.232e+03
- unit :
- mm
- description :
- Baseflow
array([[ 714.525 , 714.525 , 714.525 , ..., 714.525 , 714.525 , 714.525 ], [ 791.025 , 791.025 , 791.025 , ..., 791.025 , 791.025 , 791.025 ], [ 867.525 , 867.525 , 867.525 , ..., 867.525 , 867.525 , 867.525 ], ..., [1380.754133 , 1380.59929531, 1352.10569877, ..., 1500.94857575, 1229.91630906, 1322.0174948 ], [1335.776633 , 1335.62179531, 1307.12819877, ..., 1455.97107575, 1184.93880906, 1277.0399948 ], [1300.94382989, 1301.24977165, 1262.15069877, ..., 1410.99357575, 1139.96130906, 1232.0624948 ]], shape=(24, 81)) - bypass_flow(time_index, cell_id)float6499.29 147.3 101.4 ... 0.0 0.0 0.0
- unit :
- mm
- description :
- Bypass flow
array([[ 99.29438987, 147.29546529, 101.35486269, ..., 121.89779953, 102.97406548, 114.22478108], [108.22688866, 123.03339253, 95.29052398, ..., 131.98284312, 134.27226911, 38.49891555], [ 83.83665023, 85.43514488, 73.10794557, ..., 104.36657667, 59.97288369, 76.40358844], ..., [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 12.53988969, 17.36342772, 0. , ..., 0. , 0. , 0. ]], shape=(24, 81)) - canopy_evaporation(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- mm
- description :
- Canopy evaporation
array([[[ nan, nan, nan, ..., nan, nan, nan], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 5.42101086e-20, 0.00000000e+00, 2.16840434e-19], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.00000000e+00, 1.38777878e-17, 5.55111512e-17, ..., 2.22044605e-16, 2.77555756e-17, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [0.00000000e+00, 2.16840434e-19, 1.08420217e-19, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], ... 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [3.46944695e-18, 3.46944695e-18, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], ..., [1.77635684e-14, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - canopy_foliage_cnp(time_index, cell_id, pft, element)float641.582 0.1054 ... 4.068e-05
- unit :
- kg
- description :
- C, N, and P of canopy foliage
array([[[[1.58174120e+00, 1.05449413e-01, 5.27247066e-03], [8.20632214e-01, 5.47088143e-02, 2.73544071e-03]], [[1.26605228e+00, 8.44034855e-02, 4.22017428e-03], [8.21101759e-01, 5.47401173e-02, 2.73700586e-03]], [[1.58174120e+00, 1.05449413e-01, 5.27247066e-03], [8.21101759e-01, 5.47401173e-02, 2.73700586e-03]], ..., [[1.58174120e+00, 1.05449413e-01, 5.27247066e-03], [8.20632214e-01, 5.47088143e-02, 2.73544071e-03]], [[1.58189818e+00, 1.05459879e-01, 5.27299393e-03], [8.20632214e-01, 5.47088143e-02, 2.73544071e-03]], [[1.58205516e+00, 1.05470344e-01, 5.27351721e-03], [8.20945244e-01, 5.47296829e-02, 2.73648415e-03]]], ... [[[1.07773281e+02, 2.20812341e-02, 1.11125656e-03], [1.06654475e+02, 1.31526461e-03, 1.00459166e-04]], [[1.38876569e+02, 2.18650437e-02, 1.10461978e-03], [1.08687472e+02, 1.17843045e-03, 8.67540052e-05]], [[1.35769421e+02, 3.50407901e-02, 1.77243851e-03], [1.37746606e+02, 4.96979864e-05, 4.47821331e-06]], ..., [[1.13365860e+02, 2.74425494e-02, 1.39652007e-03], [9.34522923e+01, 9.53561384e-05, 7.59905699e-06]], [[1.09181664e+02, 2.69081087e-02, 1.37337870e-03], [1.27332129e+02, 1.00060764e-04, 7.38863950e-06]], [[1.58581955e+02, 3.29246489e-02, 1.68164900e-03], [1.08142771e+02, 1.60840157e-04, 4.06753547e-05]]]], shape=(24, 81, 2, 3)) - canopy_foliage_cnp_consumed(time_index, cell_id, pft, element)float640.001441 9.608e-05 ... 4.732e-08
- unit :
- kg
- description :
- C, N, and P of canopy foliage consumed by animals
array([[[[1.44126007e-03, 9.60840043e-05, 4.80420022e-06], [3.87972021e-04, 2.58648014e-05, 1.29324007e-06]], [[1.27996236e-03, 8.53308238e-05, 4.26654119e-06], [5.38402658e-04, 3.58935105e-05, 1.79467553e-06]], [[1.94069023e-03, 1.29379349e-04, 6.46896744e-06], [5.23011670e-04, 3.48674447e-05, 1.74337223e-06]], ..., [[1.76944141e-03, 1.17962760e-04, 5.89813802e-06], [4.76312723e-04, 3.17541815e-05, 1.58770908e-06]], [[1.94104066e-03, 1.29402710e-04, 6.47013552e-06], [5.22404473e-04, 3.48269649e-05, 1.74134824e-06]], [[1.47034208e-03, 9.80228052e-05, 4.90114026e-06], [3.95946077e-04, 2.63964051e-05, 1.31982026e-06]]], ... [[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[9.90573068e-02, 1.55958083e-05, 7.87898646e-07], [6.06659641e-02, 6.57763201e-07, 4.84233858e-08]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], ..., [[2.20300104e-01, 5.33281932e-05, 2.71381099e-06], [1.49671723e-01, 1.52720893e-07, 1.21705302e-08]], [[1.07688105e-01, 2.65400171e-05, 1.35459146e-06], [1.46427424e-01, 1.15066322e-07, 8.49667285e-09]], [[2.70551593e-01, 5.61716888e-05, 2.86900748e-06], [1.25797943e-01, 1.87098598e-07, 4.73159314e-08]]]], shape=(24, 81, 2, 3)) - canopy_fruit_cnp(time_index, cell_id, pft, element)float640.06591 0.005272 ... 3.668e-06
- unit :
- kg
- description :
- Average C, N, and P masses of each fruit per PFT in the canopy
array([[[[6.59058832e-02, 5.27247066e-03, 5.25146480e-04], [3.07737080e-02, 2.46189664e-03, 2.45208829e-04]], [[5.27521785e-02, 4.22017428e-03, 4.20336083e-04], [3.07913160e-02, 2.46330528e-03, 2.45349131e-04]], [[6.59058832e-02, 5.27247066e-03, 5.25146480e-04], [3.07913160e-02, 2.46330528e-03, 2.45349131e-04]], ..., [[6.59058832e-02, 5.27247066e-03, 5.25146480e-04], [3.07737080e-02, 2.46189664e-03, 2.45208829e-04]], [[6.59124242e-02, 5.27299393e-03, 5.25198599e-04], [3.07737080e-02, 2.46189664e-03, 2.45208829e-04]], [[6.59189651e-02, 5.27351721e-03, 5.25250718e-04], [3.07854466e-02, 2.46283573e-03, 2.45302364e-04]]], ... [[[4.50164702e+00, 1.10406172e-03, 1.10682926e-04], [4.02993744e+00, 5.91869074e-05, 9.00530375e-06]], [[5.81629139e+00, 1.09326768e-03, 1.10023451e-04], [4.10644746e+00, 5.30294690e-05, 7.77676989e-06]], [[5.72928548e+00, 1.75272801e-03, 1.76606926e-04], [5.29867435e+00, 2.23732316e-06, 4.01592825e-07]], ..., [[4.79303736e+00, 1.37450141e-03, 1.39335657e-04], [3.62523156e+00, 4.29893404e-06, 6.82424345e-07]], [[4.63937729e+00, 1.34879955e-03, 1.37134701e-04], [4.96003954e+00, 4.51697627e-06, 6.64500254e-07]], [[6.77107419e+00, 1.65450011e-03, 1.68332440e-04], [4.12914599e+00, 7.36820239e-06, 3.66804120e-06]]]], shape=(24, 81, 2, 3)) - canopy_fruit_cnp_consumed(time_index, cell_id, pft, element)float642.545e-06 2.036e-07 ... 1.629e-10
- unit :
- kg
- description :
- C, N, and P of canopy fruit consumed by animals
array([[[[2.54457654e-06, 2.03566123e-07, 2.02755103e-08], [5.54789586e-07, 4.43831668e-08, 4.42063415e-09]], [[2.25974658e-06, 1.80779726e-07, 1.80059488e-08], [7.69903703e-07, 6.15922963e-08, 6.13469086e-09]], [[3.42633602e-06, 2.74106881e-07, 2.73014822e-08], [7.47893204e-07, 5.98314563e-08, 5.95930840e-09]], ..., [[3.12395852e-06, 2.49916682e-07, 2.48920998e-08], [6.81111077e-07, 5.44888861e-08, 5.42717989e-09]], [[3.42695648e-06, 2.74156519e-07, 2.73064262e-08], [7.47025092e-07, 5.97620073e-08, 5.95239117e-09]], [[2.59593032e-06, 2.07674425e-07, 2.06847037e-08], [5.66193285e-07, 4.52954628e-08, 4.51150028e-09]]], ... [[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[1.73798536e-04, 3.26682949e-08, 3.28764730e-09], [8.66172346e-05, 1.11854979e-09, 1.64035290e-10]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], ..., [[3.93917900e-04, 1.12964008e-07, 1.14513627e-08], [2.25278734e-04, 2.67143878e-10, 4.24071374e-11]], [[1.94478119e-04, 5.65403462e-08, 5.74855135e-09], [2.22219845e-04, 2.02369711e-10, 2.97709610e-11]], [[4.93366804e-04, 1.20553314e-07, 1.22653564e-08], [1.83426081e-04, 3.27312352e-10, 1.62942754e-10]]]], shape=(24, 81, 2, 3)) - canopy_fruit_n(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of fruits of each PFT in the canopy
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - canopy_seed_cnp(time_index, cell_id, pft, element)float640.01318 0.001054 ... 1.223e-06
- unit :
- kg
- description :
- C, N, and P of each seed PFT
array([[[[1.31811766e-02, 1.05449413e-03, 1.05029296e-04], [1.02579027e-02, 8.20632214e-04, 8.17362763e-05]], [[1.05504357e-02, 8.44034855e-04, 8.40672167e-05], [1.02637720e-02, 8.21101759e-04, 8.17830437e-05]], [[1.31811766e-02, 1.05449413e-03, 1.05029296e-04], [1.02637720e-02, 8.21101759e-04, 8.17830437e-05]], ..., [[1.31811766e-02, 1.05449413e-03, 1.05029296e-04], [1.02579027e-02, 8.20632214e-04, 8.17362763e-05]], [[1.31824848e-02, 1.05459879e-03, 1.05039720e-04], [1.02579027e-02, 8.20632214e-04, 8.17362763e-05]], [[1.31837930e-02, 1.05470344e-03, 1.05050144e-04], [1.02618155e-02, 8.20945244e-04, 8.17674546e-05]]], ... [[[9.00426729e-01, 2.20812345e-04, 2.21365853e-05], [1.34371544e+00, 1.97289691e-05, 3.00176792e-06]], [[1.16352194e+00, 2.18653672e-04, 2.20047039e-05], [1.36922563e+00, 1.76764910e-05, 2.59225685e-06]], [[1.14650572e+00, 3.50551703e-04, 3.53219988e-05], [1.76805869e+00, 7.45786790e-07, 1.33866440e-07]], ..., [[9.59233336e-01, 2.74921340e-04, 2.78692607e-05], [1.21011772e+00, 1.43308574e-06, 2.27491590e-07]], [[9.28691669e-01, 2.69790215e-04, 2.74300117e-05], [1.65595510e+00, 1.50585333e-06, 2.21529749e-07]], [[1.35569110e+00, 3.30974290e-04, 3.36740112e-05], [1.37737150e+00, 2.45780820e-06, 1.22297161e-06]]]], shape=(24, 81, 2, 3)) - canopy_seed_cnp_consumed(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of canopy seed consumed by animals
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - canopy_seeds_per_fruit(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of seeds per fruit in each PFT
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - decay_of_fungal_fruiting_bodies(time_index, cell_id)float640.001131 0.001555 ... 5.81e-07
- unit :
- kg C m^-2 day^-1
- description :
- Rate of decay of fungal fruiting bodies back into the soil
array([[1.13095809e-03, 1.55506737e-03, 1.97917665e-03, ..., 1.13095809e-03, 1.13095809e-03, 1.13095809e-03], [7.40472521e-04, 1.01757316e-03, 1.29433694e-03, ..., 7.40472141e-04, 7.40473646e-04, 7.40474656e-04], [4.85611283e-04, 6.67393995e-04, 8.48948429e-04, ..., 4.85611169e-04, 4.85616302e-04, 4.85615203e-04], ..., [6.01005349e-07, 3.38010878e-06, 6.90815058e-06, ..., 5.27191867e-07, 5.50493647e-07, 6.66243750e-07], [5.35272114e-07, 3.30595222e-06, 6.50322609e-06, ..., 4.66555139e-07, 4.85644765e-07, 6.09268861e-07], [5.04259619e-07, 3.42266749e-06, 6.03024948e-06, ..., 4.31134987e-07, 4.49957530e-07, 5.81032551e-07]], shape=(24, 81)) - decomposed_carcasses_cnp(time_index, cell_id, element)float644.265e-05 2.664e-05 ... 6.615e-09
- unit :
- kg m^-2 day^-1
- description :
- Flow rates of carbon, nitrogen and phosphorous into the soil due to animal carcass decay
array([[[4.26478099e-05, 2.66436881e-05, 1.95929328e-05], [5.76067945e-05, 3.60527931e-05, 2.66326785e-05], [6.04366916e-05, 3.80908835e-05, 2.87033640e-05], ..., [6.85856236e-05, 4.24371845e-05, 3.06338782e-05], [5.36833879e-05, 3.31589621e-05, 2.37882819e-05], [5.46950594e-05, 3.39057772e-05, 2.45301329e-05]], [[2.68257403e-05, 1.83191940e-05, 1.59363561e-05], [3.29241568e-05, 2.25381690e-05, 1.97060568e-05], [4.28248015e-05, 2.92872013e-05, 2.55602691e-05], ..., [2.62194783e-05, 1.87796607e-05, 1.76321013e-05], [1.24560316e-05, 8.92900197e-06, 8.40573828e-06], [7.42687848e-05, 4.80110784e-05, 3.77791880e-05]], [[9.61647888e-05, 7.11263321e-05, 6.98183498e-05], [9.71195671e-05, 7.16828794e-05, 7.01782724e-05], [1.75428132e-04, 1.29804654e-04, 1.27522186e-04], ..., ... [1.08378330e-08, 5.41891652e-09, 1.08378330e-08], [2.08369925e-08, 1.04184963e-08, 2.08369925e-08], [7.62542145e-09, 3.81271073e-09, 7.62542145e-09]], [[5.97054275e-09, 2.98527138e-09, 5.97054275e-09], [5.97669810e-09, 2.98834905e-09, 5.97669810e-09], [9.34801856e-09, 4.67400928e-09, 9.34801856e-09], ..., [2.31184481e-08, 1.35894732e-08, 2.10881988e-08], [1.78518934e-08, 1.09552749e-08, 1.58225652e-08], [1.36993018e-08, 7.86461823e-09, 1.26843344e-08]], [[3.40710320e-09, 1.70355160e-09, 3.40710320e-09], [1.07768916e-08, 5.38844581e-09, 1.07768916e-08], [4.99708470e-09, 2.49854235e-09, 4.99708470e-09], ..., [6.88083259e-09, 3.44041629e-09, 6.88083259e-09], [2.90921945e-08, 1.75918326e-08, 2.60464592e-08], [7.62976518e-09, 4.82998733e-09, 6.61466044e-09]]], shape=(24, 81, 3)) - decomposed_excrement_cnp(time_index, cell_id, element)float643.806e-06 3.722e-07 ... 0.0
- unit :
- kg m^-2 day^-1
- description :
- Flow rates of carbon, nitrogen and phosphorous into the soil due to animal excrement decay
array([[[3.80605569e-06, 3.72193840e-07, 6.31984292e-06], [3.71091770e-06, 3.72221850e-07, 6.11320612e-06], [5.15736603e-06, 3.80088725e-07, 8.22446297e-06], ..., [3.19967546e-06, 3.97898355e-07, 5.09847525e-06], [2.67284713e-06, 4.17126258e-07, 4.29443595e-06], [4.57115806e-06, 3.82997730e-07, 7.32544251e-06]], [[9.13319548e-06, 3.87898059e-06, 0.00000000e+00], [9.26588621e-06, 3.93569240e-06, 0.00000000e+00], [1.25401156e-05, 5.33175040e-06, 0.00000000e+00], ..., [1.04278755e-05, 4.44552948e-06, 0.00000000e+00], [9.18740678e-06, 3.91827506e-06, 0.00000000e+00], [4.79111731e-05, 2.04979459e-05, 0.00000000e+00]], [[1.18009250e-05, 5.00912973e-06, 0.00000000e+00], [1.17097661e-05, 4.96865415e-06, 0.00000000e+00], [1.69023757e-05, 7.18002248e-06, 4.83135379e-29], ..., ... [5.13819269e-09, 9.58065968e-13, 0.00000000e+00], [9.84800480e-09, 1.76902977e-12, 0.00000000e+00], [1.47554435e-08, 2.66672132e-12, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.56577710e-10, 8.01624731e-14, 0.00000000e+00], ..., [9.24113622e-09, 1.61905516e-12, 0.00000000e+00], [1.54749598e-08, 2.12641825e-12, 0.00000000e+00], [1.55922262e-08, 2.14019557e-12, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [1.54189758e-08, 1.93774516e-12, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [2.70520241e-08, 3.89979349e-12, 0.00000000e+00], [1.32360191e-08, 1.52181987e-12, 0.00000000e+00], [1.78967665e-08, 2.08812045e-12, 0.00000000e+00]]], shape=(24, 81, 3)) - dissolved_ammonium(time_index, cell_id)float645.121e-05 7.351e-05 ... 0.0008573
- unit :
- kg{N} m^-3
- description :
- Concentration of dissolved ammonium in the topsoil layer
array([[5.12078990e-05, 7.35072243e-05, 8.75307352e-05, ..., 4.97481919e-05, 5.72422196e-05, 6.15719209e-05], [6.57719511e-05, 9.16459196e-05, 9.86596725e-05, ..., 6.56975215e-05, 8.40629785e-05, 7.56589225e-05], [9.52914887e-05, 1.28146088e-04, 1.23164411e-04, ..., 9.90404993e-05, 1.15186883e-04, 9.86363679e-05], ..., [5.96311382e-04, 1.67789131e-03, 4.71282480e-03, ..., 4.16797865e-04, 4.24641861e-04, 7.56105341e-04], [6.18119825e-04, 1.81429543e-03, 4.77375622e-03, ..., 4.27028946e-04, 4.32671034e-04, 8.04249981e-04], [6.43736119e-04, 2.02621859e-03, 4.72461403e-03, ..., 4.38538089e-04, 4.41512918e-04, 8.57277970e-04]], shape=(24, 81)) - dissolved_nitrate(time_index, cell_id)float640.0002019 0.0001793 ... 0.000173
- unit :
- kg{N} m^-3
- description :
- Concentration of dissolved nitrate in the topsoil layer
array([[2.01867189e-04, 1.79263721e-04, 2.41083400e-04, ..., 2.24105385e-04, 1.40343335e-04, 1.14230423e-04], [1.31251306e-04, 1.23719491e-04, 1.67833118e-04, ..., 1.29564884e-04, 1.05003586e-04, 1.31000975e-04], [1.27646149e-04, 1.19567732e-04, 1.68055751e-04, ..., 1.25306348e-04, 1.08628973e-04, 1.43699249e-04], ..., [7.97251028e-05, 2.51598639e-04, 7.92974850e-04, ..., 5.30933149e-05, 5.81406679e-05, 1.33999951e-04], [9.07278186e-05, 3.08418285e-04, 7.73246547e-04, ..., 5.56048389e-05, 6.29584267e-05, 1.45848794e-04], [1.06230115e-04, 3.96277312e-04, 9.63580284e-04, ..., 6.82022260e-05, 8.23689389e-05, 1.72966148e-04]], shape=(24, 81)) - dissolved_phosphorus(time_index, cell_id)float641.865e-07 2.599e-07 ... 6.552e-05
- unit :
- kg{P} m^-3
- description :
- Concentration of dissolved labile inorganic phosphorus in the topsoil layer
array([[1.86514175e-07, 2.59885453e-07, 3.35814349e-07, ..., 1.88387791e-07, 1.87119925e-07, 1.88242249e-07], [2.52378533e-07, 3.85395413e-07, 5.30988443e-07, ..., 2.58509920e-07, 2.54284840e-07, 2.60754431e-07], [3.32788612e-07, 5.26290191e-07, 7.60918202e-07, ..., 3.42818384e-07, 3.29050343e-07, 4.56967267e-07], ..., [2.44392535e-05, 8.09495407e-05, 2.06315469e-04, ..., 4.96614413e-06, 4.49741665e-06, 5.74954309e-05], [2.56069023e-05, 8.75762850e-05, 2.00123740e-04, ..., 5.07026997e-06, 4.57137553e-06, 6.10195664e-05], [2.72404869e-05, 9.82560674e-05, 1.91992928e-04, ..., 5.24620868e-06, 4.73781990e-06, 6.55199210e-05]], shape=(24, 81)) - ectomycorrhizal_n_supply(time_index, cell_id)float643.288e-06 2.906e-06 ... 0.0001311
- unit :
- kg{N}
- description :
- Amount of nitrogen provided by ectomycorrhizal fungi to their plant partners
array([[3.28759701e-06, 2.90625350e-06, 3.39088336e-06, ..., 3.29492974e-06, 3.32443370e-06, 3.27759004e-06], [3.96663750e-06, 3.46428612e-06, 3.75964913e-06, ..., 3.91675745e-06, 3.20866294e-06, 3.84351373e-06], [4.50494983e-06, 3.60850181e-06, 4.29389196e-06, ..., 3.53242589e-06, 3.79884226e-06, 4.33724141e-06], ..., [8.75223469e-05, 1.03102322e-04, 1.16275575e-04, ..., 8.55003824e-05, 1.01614952e-04, 1.10665907e-04], [9.60671419e-05, 1.09905603e-04, 1.26760167e-04, ..., 9.54763847e-05, 1.09583140e-04, 1.21772926e-04], [1.01865282e-04, 1.16804514e-04, 1.31072657e-04, ..., 1.01434381e-04, 1.14915538e-04, 1.31110432e-04]], shape=(24, 81)) - ectomycorrhizal_p_supply(time_index, cell_id)float644.89e-07 4.323e-07 ... 1.95e-05
- unit :
- kg{P}
- description :
- Amount of phosphorous provided by ectomycorrhizal fungi to their plant partners
array([[4.89025158e-07, 4.32300878e-07, 5.04388848e-07, ..., 4.90115890e-07, 4.94504559e-07, 4.87536635e-07], [5.90031418e-07, 5.15307400e-07, 5.59242207e-07, ..., 5.82611835e-07, 4.77283832e-07, 5.71716942e-07], [6.70104576e-07, 5.36759267e-07, 6.38710031e-07, ..., 5.25443089e-07, 5.65072126e-07, 6.45158197e-07], ..., [1.30188187e-05, 1.53363168e-05, 1.72958185e-05, ..., 1.27180545e-05, 1.51150727e-05, 1.64613887e-05], [1.42898442e-05, 1.63482948e-05, 1.88553860e-05, ..., 1.42019700e-05, 1.63003288e-05, 1.81135413e-05], [1.51523090e-05, 1.73744975e-05, 1.94968624e-05, ..., 1.50882131e-05, 1.70935151e-05, 1.95024814e-05]], shape=(24, 81)) - fallen_fruit_cnp(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- Average C, N, and P masses of each fruit per PFT
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - fallen_fruit_n(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of fallen fruits per PFT
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - fallen_seeds_cnp(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- kg
- description :
- Average C, N, and P masses of each seed in a PFT
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - fallen_seeds_per_fruit(time_index, cell_id, pft, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- count
- description :
- Number of seeds per fruit per PFT
array([[[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]], ... [[[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], ..., [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.]]]], shape=(24, 81, 2, 3)) - foliage_turnover_cnp(time_index, cell_id, pft, element)float640.03298 0.001293 ... 0.002296
- unit :
- kg
- description :
- C, N, and P masses for foliage turnover in a given timestep
array([[[[3.29755121e-02, 1.29315734e-03, 7.94590654e-05], [1.71082144e-02, 6.70910369e-04, 4.12246130e-05]], [[2.63941550e-02, 1.03506490e-03, 6.36003736e-05], [1.71180033e-02, 6.71294246e-04, 4.12482007e-05]], [[3.29755121e-02, 1.29315734e-03, 7.94590654e-05], [1.71180033e-02, 6.71294246e-04, 4.12482007e-05]], ..., [[3.29755121e-02, 1.29315734e-03, 7.94590654e-05], [1.71082144e-02, 6.70910369e-04, 4.12246130e-05]], [[3.29787848e-02, 1.29328568e-03, 7.94669514e-05], [1.71082144e-02, 6.70910369e-04, 4.12246130e-05]], [[3.29820575e-02, 1.29341402e-03, 7.94748374e-05], [1.71147403e-02, 6.71166287e-04, 4.12403381e-05]]], ... [[[6.95595187e-01, 2.72782426e-02, 1.67613298e-03], [6.81004408e-01, 2.67060552e-02, 1.64097448e-03]], [[8.94947310e-01, 3.50959729e-02, 2.15649954e-03], [6.94416948e-01, 2.72320372e-02, 1.67329385e-03]], [[9.31545743e-01, 3.65312056e-02, 2.24468854e-03], [9.52489048e-01, 3.73525117e-02, 2.29515433e-03]], ..., [[9.07575863e-01, 3.55912103e-02, 2.18692979e-03], [7.87654708e-01, 3.08884199e-02, 1.89796315e-03]], [[9.47191082e-01, 3.71447483e-02, 2.28238815e-03], [1.35155250e+00, 5.30020589e-02, 3.25675302e-03]], [[1.69348147e+00, 6.64110381e-02, 4.08067824e-03], [9.52796025e-01, 3.73645500e-02, 2.29589404e-03]]]], shape=(24, 81, 2, 3)) - foliage_turnover_cnp_consumed(time_index, cell_id, pft, element)float641.038e-05 4.072e-07 ... 2.451e-08
- unit :
- kg
- description :
- C, N, and P of foliage turnover consumed by animals
array([[[[1.03831784e-05, 4.07183466e-07, 2.50197069e-08], [2.79484049e-06, 1.09601588e-07, 6.73455541e-09]], [[6.80304643e-06, 2.66786134e-07, 1.63928830e-08], [2.86150415e-06, 1.12215849e-07, 6.89519072e-09]], [[1.05945184e-05, 4.15471310e-07, 2.55289600e-08], [2.85499122e-06, 1.11960440e-07, 6.87949692e-09]], ..., [[1.05220444e-05, 4.12629193e-07, 2.53543239e-08], [2.83221907e-06, 1.11067414e-07, 6.82462426e-09]], [[1.05966071e-05, 4.15553221e-07, 2.55339931e-08], [2.85172308e-06, 1.11832278e-07, 6.87162187e-09]], [[1.03993671e-05, 4.07818319e-07, 2.50587160e-08], [2.80022218e-06, 1.09812635e-07, 6.74752333e-09]]], ... [[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[4.28523223e-06, 1.68048323e-07, 1.03258608e-08], [2.58000306e-06, 1.01176590e-07, 6.21687483e-09]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], ..., [[1.47071374e-05, 5.76750485e-07, 3.54388852e-08], [1.10773058e-05, 4.34404148e-07, 2.66923030e-08]], [[8.44113774e-06, 3.31025009e-07, 2.03400909e-08], [1.71866567e-05, 6.73986535e-07, 4.14136305e-08]], [[3.21375881e-05, 1.26029757e-06, 7.74399714e-08], [1.01730859e-05, 3.98944546e-07, 2.45134601e-08]]]], shape=(24, 81, 2, 3)) - fruit_turnover_cnp(time_index, cell_id, pft, element)float640.001099 8.793e-05 ... 3.967e-08
- unit :
- kg C
- description :
- Biomasses of plant fruit tissue turnover
array([[[[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[8.79805168e-04, 7.03844135e-05, 7.01039975e-06], [8.55900164e-04, 6.84720131e-05, 6.81992162e-06]], [[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55900164e-04, 6.84720131e-05, 6.81992162e-06]], ..., [[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[1.09929283e-03, 8.79434262e-05, 8.75930540e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[1.09940192e-03, 8.79521534e-05, 8.76017464e-06], [8.55737016e-04, 6.84589613e-05, 6.81862164e-06]]], ... [[[2.31865062e-02, 5.78317792e-06, 5.79931196e-07], [3.40502204e-02, 5.28725738e-07, 7.94785617e-08]], [[2.98315770e-02, 5.73683248e-06, 5.77880022e-07], [3.47208474e-02, 4.68225380e-07, 6.82802566e-08]], [[2.97063234e-02, 9.22836034e-06, 9.30453744e-07], [4.48516107e-02, 3.39646557e-08, 5.37909677e-09]], ..., [[2.48964426e-02, 7.22147970e-06, 7.32334755e-07], [3.08257744e-02, 5.83749813e-08, 8.76393026e-09]], [[2.40538370e-02, 7.11181243e-06, 7.23449639e-07], [4.22323707e-02, 7.72959930e-08, 1.02079014e-08]], [[3.49423887e-02, 8.69497630e-06, 8.85001674e-07], [3.49473092e-02, 1.38859218e-07, 3.96734135e-08]]]], shape=(24, 81, 2, 3)) - fruit_turnover_cnp_consumed(time_index, cell_id, pft, element)float641.205e-08 9.64e-10 ... 1.492e-14
- unit :
- kg
- description :
- C, N, and P of fruit turnover consumed by animals
array([[[[1.20501744e-08, 9.64013956e-10, 9.60173263e-11], [7.29797094e-09, 5.83837675e-10, 5.81511628e-11]], [[7.89525729e-09, 6.31620583e-10, 6.29104167e-11], [7.47204518e-09, 5.97763615e-10, 5.95382086e-11]], [[1.22954449e-08, 9.83635590e-10, 9.79716724e-11], [7.45503840e-09, 5.96403072e-10, 5.94026964e-11]], ..., [[1.22113351e-08, 9.76906807e-10, 9.73014748e-11], [7.39557497e-09, 5.91645998e-10, 5.89288843e-11]], [[1.22978690e-08, 9.83829519e-10, 9.79909879e-11], [7.44650452e-09, 5.95720361e-10, 5.93346974e-11]], [[1.20689623e-08, 9.65516987e-10, 9.61670306e-11], [7.31202378e-09, 5.84961903e-10, 5.82631377e-11]]], ... [[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[4.57207106e-09, 8.79243017e-13, 8.85675111e-14], [6.19235669e-09, 8.35065611e-14, 1.21775744e-14]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], ..., [[1.06283286e-08, 3.08286047e-12, 3.12634801e-13], [1.62884809e-08, 3.08456086e-14, 4.63090106e-15]], [[5.22787200e-09, 1.54568459e-12, 1.57234877e-13], [1.61104098e-08, 2.94861525e-14, 3.89401475e-15]], [[1.31391149e-08, 3.26950438e-12, 3.32780303e-13], [1.31392804e-08, 5.22074586e-14, 1.49161729e-14]]]], shape=(24, 81, 2, 3)) - fungal_fruiting_bodies(time_index, cell_id)float640.06547 0.08997 ... 3.369e-05
- units :
- kg C m^-2
- description :
- Density of fungal fruiting bodies growing from the litter and soil
- unit :
- kg C m^-2
array([[6.54718303e-02, 8.99699330e-02, 1.14438753e-01, ..., 6.54718303e-02, 6.54718303e-02, 6.54718303e-02], [4.29348971e-02, 5.90020533e-02, 7.50496768e-02, ..., 4.29348751e-02, 4.29349624e-02, 4.29350209e-02], [2.81572508e-02, 3.86975772e-02, 4.92246672e-02, ..., 2.81572442e-02, 2.81575418e-02, 2.81574781e-02], ..., [3.48481572e-05, 1.95989208e-04, 4.00556032e-04, ..., 3.05682223e-05, 3.19193318e-05, 3.86308824e-05], [3.10367401e-05, 1.91689380e-04, 3.77077252e-04, ..., 2.70523164e-05, 2.81591922e-05, 3.53273013e-05], [2.92385393e-05, 1.98456894e-04, 3.49652598e-04, ..., 2.49985459e-05, 2.60899354e-05, 3.36900724e-05]], shape=(24, 81)) - groundwater_storage(time_index, groundwater_layers, cell_id)float64469.3 516.9 471.0 ... 745.5 806.9
- unit :
- mm
- description :
- Groundwater Storage
array([[[4.69280225e+02, 5.16928167e+02, 4.71047906e+02, ..., 4.92023224e+02, 4.72635814e+02, 4.83726690e+02], [5.01000000e+02, 5.01000000e+02, 5.01000000e+02, ..., 5.01000000e+02, 5.01000000e+02, 5.01000000e+02]], [[4.96973279e+02, 5.59266899e+02, 4.85711037e+02, ..., 5.43462450e+02, 5.26179538e+02, 4.41629939e+02], [5.52000000e+02, 5.52000000e+02, 5.52000000e+02, ..., 5.52000000e+02, 5.52000000e+02, 5.52000000e+02]], [[5.00069631e+02, 5.63868560e+02, 4.78083487e+02, ..., 5.67067921e+02, 5.05328612e+02, 4.37329269e+02], [6.03000000e+02, 6.03000000e+02, 6.03000000e+02, ..., 6.03000000e+02, 6.03000000e+02, 6.03000000e+02]], ..., [[5.00000000e-04, 5.00000000e-04, 5.00000000e-04, ..., 5.00000000e-04, 5.00000000e-04, 5.00000000e-04], [9.06010005e+02, 9.05906780e+02, 8.86911049e+02, ..., 9.86139634e+02, 8.05451456e+02, 8.66852247e+02]], [[5.00000000e-04, 5.00000000e-04, 5.00000000e-04, ..., 5.00000000e-04, 5.00000000e-04, 5.00000000e-04], [8.76025005e+02, 8.75921780e+02, 8.56926049e+02, ..., 9.56154634e+02, 7.75466456e+02, 8.36867247e+02]], [[5.00000000e-04, 1.26514899e+00, 5.00000000e-04, ..., 5.00000000e-04, 5.00000000e-04, 5.00000000e-04], [8.58579895e+02, 8.62035559e+02, 8.26941049e+02, ..., 9.26169634e+02, 7.45481456e+02, 8.06882247e+02]]], shape=(24, 2, 81)) - herbivory_waste_leaf_cnp(time_index, cell_id, element)float640.001093 1.542e-05 ... 3.06e-07
- unit :
- kg
- description :
- Carbon, nitrogen and phosphorus mass of leaves added to the litter due to herbivore mechanical inefficiency
array([[[1.09312616e-03, 1.54175186e-05, 1.87376462e-06], [1.12306484e-03, 1.54088362e-05, 1.90049974e-06], [1.18593454e-03, 1.97288608e-05, 2.11492735e-06], ..., [1.14827236e-03, 1.82384779e-05, 2.02833302e-06], [1.18248173e-03, 1.97215787e-05, 2.11261587e-06], [1.09335134e-03, 1.56608165e-05, 1.88444004e-06]], [[1.33584721e-04, 3.19771697e-06, 1.76372643e-07], [1.09678040e-04, 2.29483949e-06, 1.29541609e-07], [1.27032427e-04, 3.11366784e-06, 1.69793210e-07], ..., [3.56139721e-04, 8.50955798e-06, 4.69509086e-07], [2.43586922e-04, 5.18338836e-06, 2.93298623e-07], [2.65686531e-04, 6.40190099e-06, 3.52699504e-07]], [[6.15416806e-05, 9.97504732e-07, 5.43697735e-08], [2.09483170e-04, 2.97219992e-06, 1.63832892e-07], [4.25166643e-04, 7.05717582e-06, 3.78916608e-07], ..., ... [8.50263743e-03, 1.72401351e-06, 8.93729833e-08], [1.95441134e-02, 2.90554615e-06, 1.51265482e-07], [3.41808331e-02, 7.31635409e-06, 3.79944927e-07]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [3.50694560e-03, 5.24122448e-07, 2.68693417e-08], ..., [1.52522188e-02, 2.59622895e-06, 1.34700218e-07], [2.72627639e-02, 3.44541109e-06, 1.79708539e-07], [3.50816733e-02, 6.19316839e-06, 3.24165781e-07]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [1.62794293e-02, 1.65915943e-06, 8.70320436e-08], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [3.80031879e-02, 5.47224826e-06, 2.84647847e-07], [2.59477958e-02, 2.77783070e-06, 1.45520735e-07], [4.02946183e-02, 5.82122767e-06, 3.06005065e-07]]], shape=(24, 81, 3)) - herbivory_waste_leaf_lignin(time_index, cell_id)float640.25 0.25 0.25 ... 0.25 0.25 0.25
- unit :
- unitless
- description :
- Proportion of leaf carbon added to litter due to herbivore mechanical inefficiency that is lignin carbon
array([[0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25], [0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25], [0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25], ..., [0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25], [0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25], [0.25, 0.25, 0.25, ..., 0.25, 0.25, 0.25]], shape=(24, 81)) - interception(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- mm
- description :
- Intercepted rainfall in canopy
array([[[ nan, nan, nan, ..., nan, nan, nan], [4.99831148e-03, 1.40884776e-02, 1.00636686e-02, ..., 1.28492294e-02, 1.17651924e-02, 1.10742209e-02], [ nan, nan, nan, ..., nan, nan, nan], ..., [5.53021328e+00, 8.21892378e+00, 6.81996504e+00, ..., 6.99747094e+00, 6.33887572e+00, 7.69582485e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [1.05599799e-02, 1.58747423e-02, 1.04102247e-02, ..., 1.30113018e-02, 1.70990130e-02, 3.99999867e-03], [ nan, nan, nan, ..., nan, nan, nan], ... 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [1.64071499e-01, 2.37404107e-01, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], ..., [5.06787738e+02, 6.21381127e+02, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - layer_fapar(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- -
- description :
- The fraction of absorbed photosynthetically active radiation (f_APAR) in each model layer.
array([[[ nan, nan, nan, ..., nan, nan, nan], [0.00136893, 0.00118931, 0.0013692 , ..., 0.00136893, 0.00136902, 0.00136929], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.38684332, 0.3869129 , 0.38684322, ..., 0.38684332, 0.38684328, 0.38684318], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [0.00186832, 0.00164533, 0.0018796 , ..., 0.00186706, 0.0016403 , 0.0018691 ], [ nan, nan, nan, ..., nan, nan, nan], ... [0.9658403 , 0.96082578, 0.95563745, ..., 0.96644751, 0.9613803 , 0.95673867], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [0.03762632, 0.04344178, 0.04886028, ..., 0.03720742, 0.04268135, 0.04759801], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.96237368, 0.95655822, 0.95113972, ..., 0.96279258, 0.95731865, 0.95240199], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - layer_heights(time_index, layers, cell_id)float6411.31 11.31 11.31 ... -1.0 -1.0
- unit :
- m
- description :
- Heights of model layers
array([[[11.30685131, 11.30685131, 11.30685131, ..., 11.30685131, 11.30685131, 11.30685131], [ 9.30685131, 9.30685131, 9.30685131, ..., 9.30685131, 9.30685131, 9.30685131], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 0.1 , 0.1 , 0.1 , ..., 0.1 , 0.1 , 0.1 ], [-0.25 , -0.25 , -0.25 , ..., -0.25 , -0.25 , -0.25 ], [-1. , -1. , -1. , ..., -1. , -1. , -1. ]], [[12.35608049, 12.3652774 , 12.37581601, ..., 12.35434232, 12.36027949, 12.35363427], [10.35608049, 10.3652774 , 10.37581601, ..., 10.35434232, 10.36027949, 10.35363427], [ nan, nan, nan, ..., nan, nan, nan], ... [ 0.1 , 0.1 , 0.1 , ..., 0.1 , 0.1 , 0.1 ], [-0.25 , -0.25 , -0.25 , ..., -0.25 , -0.25 , -0.25 ], [-1. , -1. , -1. , ..., -1. , -1. , -1. ]], [[24.54597329, 24.49659044, 24.49247863, ..., 24.49802943, 24.4999434 , 24.52517988], [22.54597329, 22.49659044, 22.49247863, ..., 22.49802943, 22.4999434 , 22.52517988], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 0.1 , 0.1 , 0.1 , ..., 0.1 , 0.1 , 0.1 ], [-0.25 , -0.25 , -0.25 , ..., -0.25 , -0.25 , -0.25 ], [-1. , -1. , -1. , ..., -1. , -1. , -1. ]]], shape=(24, 14, 81)) - layer_leaf_mass(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- kg
- description :
- The leaf mass within each canopy layer.
array([[[ nan, nan, nan, ..., nan, nan, nan], [ 2.40237341, 2.08715404, 2.40284296, ..., 2.40237341, 2.40253039, 2.40300041], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [ 3.27665176, 2.8854415 , 3.29571902, ..., 3.27394955, 2.87612577, 3.27797881], [ nan, nan, nan, ..., nan, nan, nan], ... [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [66.03155347, 76.23726705, 85.72799493, ..., 65.23291621, 74.76290224, 83.35952331], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - leaf_area_index(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- m m-1
- description :
- Leaf area index
array([[[ nan, nan, nan, ..., nan, nan, nan], [4.15225034e-03, 3.60742674e-03, 4.15306190e-03, ..., 4.15225034e-03, 4.15252167e-03, 4.15333404e-03], [ nan, nan, nan, ..., nan, nan, nan], ..., [9.80000000e-01, 9.80000000e-01, 9.80000000e-01, ..., 9.80000000e-01, 9.80000000e-01, 9.80000000e-01], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [5.66334872e-03, 4.98718284e-03, 5.69630448e-03, ..., 5.65867823e-03, 4.97108159e-03, 5.66564239e-03], [ nan, nan, nan, ..., nan, nan, nan], ... 3.14642323e+02, 3.13654070e+02, 3.14226532e+02], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [1.14128611e-01, 1.31768116e-01, 1.48171843e-01, ..., 1.12748250e-01, 1.29219831e-01, 1.44078188e-01], [ nan, nan, nan, ..., nan, nan, nan], ..., [3.20794842e+02, 3.20757277e+02, 3.19500528e+02, ..., 3.21571934e+02, 3.20362269e+02, 3.21006336e+02], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - lignin_above_structural(time_index, cell_id)float640.01001 0.1213 ... 0.1451 0.1538
- unit :
- unitless
- description :
- Proportion of above ground structural litter carbon which is lignin carbon
array([[0.01000823, 0.12125179, 0.23250032, ..., 0.01000826, 0.01000825, 0.01000826], [0.01002432, 0.12125472, 0.23250066, ..., 0.01002503, 0.01002361, 0.01002472], [0.01005266, 0.12125909, 0.23250113, ..., 0.01005334, 0.01005096, 0.01005512], ..., [0.09518238, 0.12619108, 0.23281258, ..., 0.10488107, 0.11791367, 0.1225101 ], [0.10796421, 0.12721401, 0.23284891, ..., 0.117154 , 0.13134766, 0.13896972], [0.12087154, 0.12846333, 0.23288768, ..., 0.1314733 , 0.14505677, 0.15379468]], shape=(24, 81)) - lignin_below_structural(time_index, cell_id)float640.01026 0.1216 ... 0.1911 0.1877
- unit :
- unitless
- description :
- Proportion of below ground structural litter carbon which is lignin carbon
array([[0.01026055, 0.12162827, 0.23257955, ..., 0.01025885, 0.01026231, 0.01026583], [0.01070309, 0.1217963 , 0.23262914, ..., 0.01070001, 0.01174258, 0.01072301], [0.0114741 , 0.12198118, 0.23259034, ..., 0.01344186, 0.01244763, 0.01151231], ..., [0.18386819, 0.18044186, 0.21708394, ..., 0.18250199, 0.18730426, 0.18308884], [0.18593296, 0.18403716, 0.21512853, ..., 0.18480374, 0.19001154, 0.18558799], [0.18812274, 0.185726 , 0.21394522, ..., 0.18685858, 0.19114588, 0.1877231 ]], shape=(24, 81)) - lignin_woody(time_index, cell_id)float640.01 0.1213 ... 0.03174 0.01753
- unit :
- unitless
- description :
- Proportion of dead wood carbon which is lignin carbon
array([[0.01 , 0.12132016, 0.2325 , ..., 0.01 , 0.01 , 0.01 ], [0.01 , 0.12132016, 0.2325 , ..., 0.01 , 0.01017042, 0.01 ], [0.01 , 0.12132016, 0.2325 , ..., 0.01025858, 0.01017042, 0.01 ], ..., [0.02727203, 0.12803688, 0.23319091, ..., 0.02491165, 0.02711575, 0.01752952], [0.02727203, 0.12936957, 0.23379675, ..., 0.02491165, 0.0317399 , 0.01752952], [0.02788831, 0.12936957, 0.23379675, ..., 0.02491165, 0.0317399 , 0.01752952]], shape=(24, 81)) - litter_consumed_above_metabolic_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of above-ground metabolic litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - litter_consumed_above_structural_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of above-ground structural litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - litter_consumed_below_metabolic_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of below-ground metabolic litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - litter_consumed_below_structural_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of below-ground structural litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - litter_consumed_woody_cnp(time_index, cell_id, element)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- units :
- kg m^-2
- description :
- Amount of woody litter that has been consumed by animals, in carbon, nitrogen and phosphorus terms
- unit :
- kg
array([[[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., ... ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]], [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.], ..., [0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]], shape=(24, 81, 3)) - litter_mineralisation_rate_cnp(time_index, cell_id, element)float640.02614 0.002579 ... 1.456e-05
- unit :
- kg m^-3 day^-1
- description :
- Rate of carbon, nitrogen and phosphorus addition to soil from litter
array([[[2.61400904e-02, 2.57913564e-03, 2.57913564e-04], [2.07109864e-02, 2.57995374e-03, 2.57995374e-04], [1.75862772e-02, 2.67485748e-03, 2.67485748e-04], ..., [2.59718643e-02, 2.55688292e-03, 2.55688292e-04], [2.55334222e-02, 2.54024962e-03, 2.54024962e-04], [2.66308502e-02, 2.64353090e-03, 2.64353090e-04]], [[3.14905599e-02, 2.48185638e-03, 2.48182136e-04], [2.51565617e-02, 2.18563018e-03, 2.18552342e-04], [2.05576752e-02, 2.05577372e-03, 2.05573761e-04], ..., [3.13968604e-02, 2.48492199e-03, 2.48488669e-04], [3.50242247e-02, 2.74551325e-03, 2.74547455e-04], [3.21771548e-02, 2.51445932e-03, 2.51442329e-04]], [[3.60357379e-02, 2.42849669e-03, 2.42844258e-04], [2.88510045e-02, 1.83630763e-03, 1.83620280e-04], [2.08764688e-02, 1.32820092e-03, 1.32815021e-04], ..., ... [1.77327285e-03, 1.03370330e-04, 1.03156671e-05], [1.56273630e-03, 9.03636853e-05, 9.01341431e-06], [1.87460512e-03, 1.10858120e-04, 1.10555692e-05]], [[1.85844106e-03, 1.07610161e-04, 1.07374491e-05], [2.66536046e-03, 1.35263063e-04, 1.34991719e-05], [2.53262950e-03, 1.15162459e-04, 1.14840079e-05], ..., [1.78691958e-03, 1.04038965e-04, 1.03780966e-05], [1.68931838e-03, 9.74684251e-05, 9.71487345e-06], [2.01489033e-03, 1.18969355e-04, 1.18563114e-05]], [[2.53893732e-03, 1.46906648e-04, 1.46556113e-05], [3.89158673e-03, 1.96666260e-04, 1.96240228e-05], [4.14119526e-03, 1.87608535e-04, 1.87074673e-05], ..., [2.39258105e-03, 1.39226166e-04, 1.38841874e-05], [2.67504703e-03, 1.52980481e-04, 1.52413421e-05], [2.47829458e-03, 1.46181734e-04, 1.45605873e-05]]], shape=(24, 81, 3)) - litter_pool_above_metabolic_cnp(time_index, cell_id, element)float640.02132 0.004262 ... 1.383e-06
- unit :
- kg m^-2
- description :
- Above ground metabolic litter pool, carbon, nitrogen and phosphorus mass
array([[[2.13156682e-02, 4.26235736e-03, 4.26226876e-04], [4.68279574e-02, 7.97017033e-03, 7.97009346e-04], [7.16750701e-02, 1.06180135e-02, 1.06179247e-03], ..., [2.14148640e-02, 4.28219599e-03, 4.28210724e-04], [2.18234095e-02, 4.36390469e-03, 4.36381587e-04], [2.10282988e-02, 4.20488331e-03, 4.20479467e-04]], [[6.52057606e-03, 1.30266720e-03, 1.30249853e-04], [1.40409517e-02, 2.38891740e-03, 2.38876840e-04], [1.99559862e-02, 2.95545450e-03, 2.95528061e-04], ..., [6.58937402e-03, 1.31638468e-03, 1.31621113e-04], [5.81420838e-03, 1.16152037e-03, 1.16136649e-04], [6.23696063e-03, 1.24594604e-03, 1.24577761e-04]], [[1.35994122e-03, 2.70260124e-04, 2.70058176e-05], [2.83017862e-03, 4.80509556e-04, 4.80332396e-05], [4.15020630e-03, 6.13694252e-04, 6.13491360e-05], ..., ... [2.71701956e-04, 1.25730911e-05, 7.72557949e-07], [3.55828029e-04, 1.64266491e-05, 1.00934111e-06], [3.84937507e-04, 1.77231398e-05, 1.08899677e-06]], [[2.53843797e-04, 1.18175484e-05, 7.26138519e-07], [3.02579372e-04, 1.40804942e-05, 8.65186723e-07], [4.06308356e-04, 1.88633104e-05, 1.15906772e-06], ..., [3.07996626e-04, 1.42379792e-05, 8.74857505e-07], [4.19128876e-04, 1.93282227e-05, 1.18762948e-06], [4.64097631e-04, 2.13707129e-05, 1.31312491e-06]], [[2.52885700e-04, 1.17729448e-05, 7.23397814e-07], [2.94357828e-04, 1.36430608e-05, 8.38306681e-07], [3.72311677e-04, 1.73089422e-05, 1.06356006e-06], ..., [3.21278224e-04, 1.47732228e-05, 9.07743110e-07], [4.13687873e-04, 1.90858757e-05, 1.17273998e-06], [4.89038514e-04, 2.25105104e-05, 1.38316249e-06]]], shape=(24, 81, 3)) - litter_pool_above_structural_cnp(time_index, cell_id, element)float640.04012 0.001605 ... 1.151e-06
- unit :
- kg m^-2
- description :
- Above ground structural litter pool, carbon, nitrogen and phosphorus mass
array([[[4.01202773e-02, 1.60477190e-03, 1.60476742e-04], [9.41142286e-02, 3.20386093e-03, 3.20385703e-04], [1.51594251e-01, 4.49165545e-03, 4.49165095e-04], ..., [4.01684047e-02, 1.60669692e-03, 1.60669243e-04], [4.03648920e-02, 1.61455636e-03, 1.61455187e-04], [3.99799109e-02, 1.59915723e-03, 1.59915276e-04]], [[2.95459345e-02, 1.18174896e-03, 1.18173870e-04], [7.87422100e-02, 2.68051999e-03, 2.68051053e-04], [1.36003084e-01, 4.02965607e-03, 4.02964471e-04], ..., [2.96260349e-02, 1.18495067e-03, 1.18494014e-04], [2.86841583e-02, 1.14728345e-03, 1.14727384e-04], [2.92084666e-02, 1.16825008e-03, 1.16823980e-04]], [[1.96972443e-02, 7.87760672e-04, 7.87745629e-05], [6.21096405e-02, 2.11426876e-03, 2.11425405e-04], [1.19022462e-01, 3.52648793e-03, 3.52646974e-04], ..., ... [4.40040535e-04, 1.24769325e-05, 1.18833038e-06], [5.07296598e-04, 1.35862018e-05, 1.28101246e-06], [5.00629575e-04, 1.31592158e-05, 1.23661271e-06]], [[3.77161045e-04, 1.04474829e-05, 9.90542573e-07], [4.54234271e-03, 1.49634630e-04, 1.48910871e-05], [2.58794340e-02, 7.59814281e-04, 7.58590379e-05], ..., [4.49480916e-04, 1.20698846e-05, 1.13854875e-06], [5.29752812e-04, 1.33278172e-05, 1.24184508e-06], [5.32738901e-04, 1.29409807e-05, 1.19746567e-06]], [[3.78234267e-04, 9.86138139e-06, 9.24569717e-07], [4.22918876e-03, 1.38381449e-04, 1.37573069e-05], [2.47052683e-02, 7.24422153e-04, 7.23091421e-05], ..., [4.58510112e-04, 1.15460993e-05, 1.07610934e-06], [5.44351819e-04, 1.27822078e-05, 1.17421979e-06], [5.61976022e-04, 1.26471681e-05, 1.15124048e-06]]], shape=(24, 81, 3)) - litter_pool_below_metabolic_cnp(time_index, cell_id, element)float640.01583 0.003161 ... 6.363e-13
- unit :
- kg m^-2
- description :
- Below ground metabolic litter pool, carbon, nitrogen and phosphorus mass
array([[[1.58314590e-02, 3.16131105e-03, 3.16098821e-04], [1.86647619e-02, 3.16673228e-03, 3.16592167e-04], [2.22572702e-02, 3.29395711e-03, 3.29363421e-04], ..., [1.62409759e-02, 3.24321442e-03, 3.24289158e-04], [1.54282811e-02, 3.08067513e-03, 3.08035227e-04], [1.46589503e-02, 2.92680799e-03, 2.92648507e-04]], [[6.43414725e-03, 1.28077318e-03, 1.28043999e-04], [6.98673566e-03, 1.18253644e-03, 1.18205475e-04], [8.11512266e-03, 1.19817311e-03, 1.19784700e-04], ..., [6.50161579e-03, 1.29429360e-03, 1.29396220e-04], [5.27374591e-03, 1.03858205e-03, 1.03774255e-04], [5.67900300e-03, 1.12983258e-03, 1.12950503e-04]], [[1.85891950e-03, 3.69377841e-04, 3.69237560e-05], [1.88182033e-03, 3.18323378e-04, 3.18176968e-05], [2.34788999e-03, 3.46101474e-04, 3.45951483e-05], ..., ... [8.93170545e-11, 1.73543640e-11, 1.73266283e-12], [6.85861467e-11, 1.34885816e-11, 1.34763837e-12], [9.29529835e-11, 1.84522427e-11, 1.84441824e-12]], [[3.31949258e-11, 6.59601990e-12, 6.59351490e-13], [3.74390505e-11, 6.33308337e-12, 6.33017054e-13], [6.74298432e-11, 9.93980476e-12, 9.93549711e-13], ..., [5.62231375e-11, 1.09241936e-11, 1.09067346e-12], [4.40522124e-11, 8.66358426e-12, 8.65574971e-13], [5.74463299e-11, 1.14037612e-11, 1.13987798e-12]], [[1.75991938e-11, 3.49705957e-12, 3.49573147e-13], [1.95532248e-11, 3.30756793e-12, 3.30604665e-13], [3.52200585e-11, 5.19177398e-12, 5.18952400e-13], ..., [3.09665570e-11, 6.01682293e-12, 6.00720686e-13], [2.34700808e-11, 4.61577322e-12, 4.61159914e-13], [3.20662260e-11, 6.36551688e-12, 6.36273630e-13]]], shape=(24, 81, 3)) - litter_pool_below_structural_cnp(time_index, cell_id, element)float640.04243 0.001696 ... 3.565e-06
- unit :
- kg m^-2
- description :
- Below ground structural litter pool, carbon, nitrogen and phosphorus mass
array([[[4.24320521e-02, 1.69641039e-03, 1.69635389e-04], [5.38801541e-02, 1.83242440e-03, 1.83228253e-04], [6.51127448e-02, 1.92866863e-03, 1.92861211e-04], ..., [4.27116963e-02, 1.70759615e-03, 1.70753965e-04], [4.21514344e-02, 1.68518562e-03, 1.68512912e-04], [4.16004773e-02, 1.66314717e-03, 1.66309065e-04]], [[3.37011646e-02, 1.34551238e-03, 1.34537521e-04], [4.66599128e-02, 1.58550505e-03, 1.58529707e-04], [5.98353810e-02, 1.77105761e-03, 1.77091016e-04], ..., [3.37919403e-02, 1.34914794e-03, 1.34901103e-04], [3.20570587e-02, 1.27611336e-03, 1.27579273e-04], [3.26360414e-02, 1.30291599e-03, 1.30277929e-04]], [[2.45932167e-02, 9.78754999e-04, 9.78445475e-05], [3.85539679e-02, 1.30777502e-03, 1.30739499e-04], [5.39692942e-02, 1.59530861e-03, 1.59496412e-04], ..., ... [9.67612510e-03, 3.70701102e-05, 3.66887208e-06], [1.22933960e-02, 3.42043492e-05, 3.38453273e-06], [1.09541430e-02, 4.07235895e-05, 4.02222865e-06]], [[1.10346502e-02, 3.43700171e-05, 3.38784402e-06], [1.63467791e-02, 1.15634946e-04, 1.14930725e-05], [2.53484796e-02, 3.50430620e-04, 3.49550666e-05], ..., [1.05564428e-02, 3.51957071e-05, 3.48129099e-06], [1.48167425e-02, 3.25060140e-05, 3.21445476e-06], [1.21475950e-02, 3.85785680e-05, 3.80790412e-06]], [[1.21396668e-02, 3.19827904e-05, 3.15101604e-06], [1.69771451e-02, 1.07444553e-04, 1.06774736e-05], [2.58369618e-02, 3.29331889e-04, 3.28479696e-05], ..., [1.13947167e-02, 3.29208814e-05, 3.25439296e-06], [1.55860992e-02, 3.03771425e-05, 3.00208512e-06], [1.33281545e-02, 3.61386064e-05, 3.56491420e-06]]], shape=(24, 81, 3)) - litter_pool_woody_cnp(time_index, cell_id, element)float644.44 0.148 ... 0.02805 0.002805
- unit :
- kg m^-2
- description :
- Woody litter pool, carbon, nitrogen and phosphorus mass
array([[[4.43953074e+00, 1.47984358e-01, 1.47984358e-02], [5.45036971e+00, 1.55713932e-01, 1.55709602e-02], [6.42399681e+00, 1.60599920e-01, 1.60599920e-02], ..., [4.44116505e+00, 1.48038835e-01, 1.48038835e-02], [4.44782358e+00, 1.48260786e-01, 1.48260786e-02], [4.43475617e+00, 1.47825206e-01, 1.47825206e-02]], [[4.04143493e+00, 1.34714498e-01, 1.34714498e-02], [5.16004654e+00, 1.47419566e-01, 1.47415465e-02], [6.21344469e+00, 1.55336117e-01, 1.55336117e-02], ..., [4.04479314e+00, 1.34826438e-01, 1.34826438e-02], [4.00608663e+00, 1.33507263e-01, 1.33503386e-02], [4.02720487e+00, 1.34240162e-01, 1.34240162e-02]], [[3.56823033e+00, 1.18941011e-01, 1.18941011e-02], [4.79758176e+00, 1.37064155e-01, 1.37060342e-02], [5.96413638e+00, 1.49103410e-01, 1.49103410e-02], ..., ... [9.21294607e-01, 2.98581896e-02, 2.98570188e-03], [9.27673594e-01, 2.99368443e-02, 2.99358864e-03], [9.14112245e-01, 3.00431331e-02, 3.00426590e-03]], [[8.87376624e-01, 2.86351396e-02, 2.86320569e-03], [2.17054883e+00, 6.08471816e-02, 6.08413476e-03], [3.73380584e+00, 9.29578009e-02, 9.29578009e-03], ..., [8.97100014e-01, 2.90740683e-02, 2.90729282e-03], [9.13109649e-01, 2.92037454e-02, 2.92028109e-03], [8.86896565e-01, 2.91486649e-02, 2.91482049e-03]], [[8.54053387e-01, 2.75270115e-02, 2.75240481e-03], [2.11815092e+00, 5.93783065e-02, 5.93726133e-03], [3.67916586e+00, 9.15974698e-02, 9.15974698e-03], ..., [8.64735950e-01, 2.80251830e-02, 2.80240841e-03], [8.77153597e-01, 2.80537725e-02, 2.80528748e-03], [8.53492242e-01, 2.80508013e-02, 2.80503587e-03]]], shape=(24, 81, 3)) - matric_potential(time_index, layers, cell_id)float64nan nan nan ... -55.26 -53.8 -54.68
- unit :
- kPa
- description :
- Matric potential
array([[[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [-263.61176629, -182.56917152, -196.258768 , ..., -295.93117543, -189.07616467, -153.07487275], [ -51.16671099, -50.46269438, -50.55561765, ..., -51.3201372 , -50.45353306, -50.24058197]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ... nan, nan, nan], [ -35.86935681, -34.71976627, -39.98037801, ..., -35.89190276, -39.23863662, -38.63994439], [ -54.736607 , -53.52955649, -54.49007899, ..., -54.94887636, -53.4609818 , -54.29785792]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [ -34.62787988, -33.44986247, -40.03486818, ..., -35.94928581, -39.29367062, -38.69533828], [ -55.03941053, -53.87889496, -54.86781503, ..., -55.2648611 , -53.80294733, -54.6823495 ]]], shape=(24, 14, 81)) - net_radiation(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- W m-2
- description :
- Net radiation
array([[[ nan, nan, nan, ..., nan, nan, nan], [ 2.77708930e+00, 2.77836147e+00, 2.77839113e+00, ..., 2.77726963e+00, 2.77799274e+00, 2.77655598e+00], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 7.89145116e+02, 7.89146387e+02, 7.89146416e+02, ..., 7.89145296e+02, 7.89146018e+02, 7.89144583e+02], [ 1.24803095e+03, 1.24803200e+03, 1.24803288e+03, ..., 1.24803183e+03, 1.24803196e+03, 1.24803122e+03], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [ 2.76158151e+00, 2.39406368e+00, 2.75670491e+00, ..., 2.76190459e+00, 2.75360687e+00, 2.76056942e+00], [ nan, nan, nan, ..., nan, nan, nan], ... 1.97852573e+03, 1.96742646e+03, 1.95998957e+03], [-5.53748080e-03, -5.55239587e-03, -4.47158188e-03, ..., -5.15980352e-03, -5.12680308e-03, -5.33717639e-03], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [ 6.96800063e+01, 7.99091576e+01, 9.04930720e+01, ..., 6.84422927e+01, 7.87778082e+01, 8.82481943e+01], [ nan, nan, nan, ..., nan, nan, nan], ..., [ 1.97030859e+03, 1.96007856e+03, 1.94949414e+03, ..., 1.97154828e+03, 1.96120966e+03, 1.95174218e+03], [-8.58047322e-03, -8.69320554e-03, -9.41686294e-03, ..., -7.98349499e-03, -8.27747901e-03, -7.49083966e-03], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - plant_ammonium_uptake(time_index, cell_id)float645.439e-16 8.293e-16 ... 9.507e-13
- units :
- kg N m^-3
- description :
- Rate at which plants uptake ammonium from the soil
- unit :
- kg N m^-2 day^-1
array([[5.43898036e-16, 8.29327407e-16, 1.03885974e-15, ..., 5.54407437e-16, 5.57350500e-16, 5.36273730e-16], [4.66453473e-16, 6.20991689e-16, 7.67509521e-16, ..., 4.90497468e-16, 4.67500150e-16, 6.04871704e-16], [3.88104269e-17, 7.16365911e-16, 4.91983334e-16, ..., 4.88130234e-16, 5.56885835e-16, 3.90514561e-16], ..., [5.43727156e-13, 1.80589447e-12, 4.89155114e-12, ..., 4.01074650e-13, 4.20550595e-13, 7.80459060e-13], [6.04369450e-13, 2.12608369e-12, 5.51945373e-12, ..., 4.50380904e-13, 4.73106048e-13, 9.10285521e-13], [6.03688712e-13, 2.14401013e-12, 5.15817466e-12, ..., 4.81369585e-13, 4.48495199e-13, 9.50673079e-13]], shape=(24, 81)) - plant_nitrate_uptake(time_index, cell_id)float641.088e-14 1.659e-14 ... 1.724e-13
- units :
- kg N m^-3
- description :
- Rate at which plants uptake nitrate from the soil
- unit :
- kg N m^-2 day^-1
array([[1.08779607e-14, 1.65865481e-14, 2.07771949e-14, ..., 1.10881487e-14, 1.11470100e-14, 1.07254746e-14], [1.83881106e-15, 1.51442640e-15, 2.11392952e-15, ..., 2.20959034e-15, 1.14619123e-15, 1.12217955e-15], [7.74481998e-17, 9.67074436e-16, 8.36928555e-16, ..., 9.62662453e-16, 6.95609539e-16, 6.76163320e-16], ..., [7.79425429e-14, 2.97722918e-13, 9.96862578e-13, ..., 4.97079278e-14, 5.99038985e-14, 1.37541642e-13], [8.08024431e-14, 3.18804776e-13, 9.28697370e-13, ..., 5.73712517e-14, 6.47762365e-14, 1.61324367e-13], [8.86096155e-14, 3.64467615e-13, 8.35514123e-13, ..., 6.26807116e-14, 6.52610180e-14, 1.72402270e-13]], shape=(24, 81)) - plant_phosphorus_uptake(time_index, cell_id)float641.36e-18 1.555e-18 ... 7.213e-14
- units :
- kg P m^-3
- description :
- Rate at which plants uptake labile inorganic phosphorus from the soil
- unit :
- kg P m^-2 day^-1
array([[1.35974509e-18, 1.55498889e-18, 1.62321835e-18, ..., 1.38601859e-18, 1.39337625e-18, 1.34068433e-18], [1.69896024e-18, 2.19552171e-18, 2.94457381e-18, ..., 1.85742900e-18, 1.52821805e-18, 1.84925869e-18], [1.48922427e-19, 3.01250876e-18, 2.64786471e-18, ..., 1.92071946e-18, 1.68454209e-18, 1.34588756e-18], ..., [2.21928964e-14, 8.74987017e-14, 2.22972864e-13, ..., 4.80656008e-15, 4.48463599e-15, 5.96838706e-14], [2.47695057e-14, 1.02572495e-13, 2.41627630e-13, ..., 5.36628585e-15, 5.01070482e-15, 6.92195325e-14], [2.50090634e-14, 1.03491658e-13, 2.16239195e-13, ..., 5.71547614e-15, 4.73856537e-15, 7.21288908e-14]], shape=(24, 81)) - plant_reproductive_tissue_lignin(time_index, cell_id)float640.01 0.01 0.01 ... 0.01 0.01 0.01
- units :
- m
- description :
- Proportion of carbon in reproductive tissue turnover that is lignin carbon
- unit :
- unitless
array([[0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01], [0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01], [0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01], ..., [0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01], [0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01], [0.01, 0.01, 0.01, ..., 0.01, 0.01, 0.01]], shape=(24, 81)) - plant_symbiote_carbon_supply(time_index, cell_id)float649.835e-09 8.62e-09 ... 3.571e-07
- units :
- m
- description :
- Rate at which plants are supplying carbon to their soil-living symbiotic partners
- unit :
- kg C m^-2 day^-1
array([[9.83516702e-09, 8.61951543e-09, 1.00220357e-08, ..., 9.81889309e-09, 9.87513400e-09, 9.81482530e-09], [1.26210326e-08, 1.11264153e-08, 1.22602125e-08, ..., 1.25144796e-08, 1.05722539e-08, 1.23369227e-08], [1.55464745e-08, 1.24985182e-08, 1.48062535e-08, ..., 1.23151522e-08, 1.29541053e-08, 1.49214527e-08], ..., [2.24698549e-07, 2.62322210e-07, 2.97442115e-07, ..., 2.22413763e-07, 2.60602156e-07, 2.89563698e-07], [2.52836501e-07, 2.88667282e-07, 3.28210429e-07, ..., 2.49461507e-07, 2.84915596e-07, 3.20759500e-07], [2.81072875e-07, 3.23442904e-07, 3.64878906e-07, ..., 2.76900453e-07, 3.17774721e-07, 3.57139658e-07]], shape=(24, 81)) - precipitation_surface(time_index, cell_id)float64251.6 249.4 229.9 ... 0.0 0.0 0.0
- unit :
- mm
- description :
- Precipitation that reaches surface
array([[251.5812999 , 249.38663955, 229.94329074, ..., 203.64441997, 185.09274426, 255.28981254], [379.93455291, 378.97248327, 443.99066142, ..., 462.85986626, 458.90887372, 414.37306839], [626.59189539, 594.96869526, 607.21868131, ..., 544.55372695, 592.69870621, 589.54523377], ..., [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 31.66191698, 39.62479443, 0. , ..., 0. , 0. , 0. ]], shape=(24, 81)) - production_of_fungal_fruiting_bodies(time_index, cell_id)float643.94e-08 1.48e-07 ... 5.846e-07
- unit :
- kg C m^-2 day^-1
- description :
- Rate at which fungal fruiting bodies are produced by soil fungi
array([[3.93964373e-08, 1.47955202e-07, 2.39966015e-07, ..., 3.82935207e-08, 4.26648256e-08, 4.55990784e-08], [1.03394942e-07, 3.06484863e-07, 4.88156719e-07, ..., 1.03788908e-07, 1.15833753e-07, 1.10714755e-07], [1.55388204e-07, 4.47519378e-07, 6.84681229e-07, ..., 1.57663671e-07, 1.64501043e-07, 1.61111170e-07], ..., [4.10051016e-07, 3.16468478e-06, 5.73184935e-06, ..., 3.51042830e-07, 3.62108351e-07, 5.00732317e-07], [4.45181154e-07, 3.64500880e-06, 5.12923416e-06, ..., 3.63659984e-07, 3.81973735e-07, 5.27242688e-07], [5.03124946e-07, 4.35606055e-06, 4.06205999e-06, ..., 4.03995834e-07, 4.38011499e-07, 5.84592894e-07]], shape=(24, 81)) - relative_humidity(time_index, layers, cell_id)float6484.26 84.32 87.01 ... nan nan nan
- unit :
- %
- description :
- Relative humidity profile
array([[[84.26389887, 84.31929038, 87.00965838, ..., 83.35697745, 83.72106275, 84.49945442], [84.27893374, 84.33432525, 87.02469325, ..., 83.37201232, 83.73609762, 84.51448929], [ nan, nan, nan, ..., nan, nan, nan], ..., [84.28637422, 84.34176573, 87.03213373, ..., 83.3794528 , 83.7435381 , 84.52192977], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[92.26397245, 93.49008521, 91.87819927, ..., 90.48482703, 92.57059903, 89.96444247], [92.27900831, 93.50314819, 91.89323807, ..., 90.49986289, 92.58563587, 89.97948225], [ nan, nan, nan, ..., nan, nan, nan], ... [71.13743949, 69.18577941, 72.18465652, ..., 73.92694234, 70.90098319, 72.02449203], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[78.31734493, 77.86915833, 79.48430283, ..., 74.82441758, 78.06218489, 78.45826725], [78.52953627, 78.11289199, 79.76035436, ..., 75.03308937, 78.30211759, 78.72659183], [ nan, nan, nan, ..., nan, nan, nan], ..., [78.87757538, 78.51151587, 80.21169331, ..., 75.37435411, 78.69460677, 79.16617847], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - river_discharge_rate(time_index, cell_id)float640.0007866 0.0003163 ... 0.0009049
- unit :
- m3 s-1
- description :
- River discharge rate
array([[0.00078659, 0.00031634, 0.00015841, ..., 0.00015074, 0.00045733, 0.00108393], [0.00095081, 0.00038805, 0.00019436, ..., 0.00019775, 0.00058389, 0.00135257], [0.00112561, 0.0004527 , 0.00022022, ..., 0.00022363, 0.00066113, 0.00151846], ..., [0.00070014, 0.00028466, 0.00014084, ..., 0.00015635, 0.00041564, 0.00097054], [0.00067671, 0.00027529, 0.00013616, ..., 0.00015166, 0.00040158, 0.00093774], [0.00066298, 0.00026941, 0.00013147, ..., 0.00014698, 0.00038753, 0.00090494]], shape=(24, 81)) - root_carbohydrate_exudation(time_index, cell_id)float649.835e-09 8.62e-09 ... 3.571e-07
- units :
- m
- description :
- Rate at which plants exude carbohydrates from their roots into the soil
- unit :
- kg C m^-2 day^-1
array([[9.83516702e-09, 8.61951543e-09, 1.00220357e-08, ..., 9.81889309e-09, 9.87513400e-09, 9.81482530e-09], [1.26210326e-08, 1.11264153e-08, 1.22602125e-08, ..., 1.25144796e-08, 1.05722539e-08, 1.23369227e-08], [1.55464745e-08, 1.24985182e-08, 1.48062535e-08, ..., 1.23151522e-08, 1.29541053e-08, 1.49214527e-08], ..., [2.24698549e-07, 2.62322210e-07, 2.97442115e-07, ..., 2.22413763e-07, 2.60602156e-07, 2.89563698e-07], [2.52836501e-07, 2.88667282e-07, 3.28210429e-07, ..., 2.49461507e-07, 2.84915596e-07, 3.20759500e-07], [2.81072875e-07, 3.23442904e-07, 3.64878906e-07, ..., 2.76900453e-07, 3.17774721e-07, 3.57139658e-07]], shape=(24, 81)) - root_lignin(time_index, cell_id)float640.2 0.2 0.2 0.2 ... 0.2 0.2 0.2 0.2
- units :
- m
- description :
- Proportion of carbon in root turnover that is lignin carbon
- unit :
- unitless
array([[0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2], [0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2], [0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2], ..., [0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2], [0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2], [0.2, 0.2, 0.2, ..., 0.2, 0.2, 0.2]], shape=(24, 81)) - root_turnover_cnp(time_index, cell_id, element)float640.4585 0.01005 ... 4.778e-05
- unit :
- kg
- description :
- C, N, and P masses for root turnover in a given timestep
array([[[4.58458727e-01, 1.00539195e-02, 6.98125061e-04], [1.15113769e+00, 2.52442476e-02, 1.75291258e-03], [4.58548333e-01, 1.00558845e-02, 6.98261510e-04], ..., [4.58458727e-01, 1.00539195e-02, 6.98125061e-04], [4.58488685e-01, 1.00545764e-02, 6.98170680e-04], [4.58578380e-01, 1.00565434e-02, 6.98307264e-04]], [[6.26358523e-01, 7.94953382e-03, 5.56140363e-04], [5.55305896e-01, 6.96821560e-03, 4.82669768e-04], [6.30361270e-01, 8.02620355e-03, 5.56149248e-04], ..., [6.26083177e-01, 7.95176986e-03, 5.56300728e-04], [1.98872016e+00, 2.72302248e-02, 1.90590736e-03], [6.26631808e-01, 7.95949244e-03, 5.56670612e-04]], [[8.09517268e-01, 6.90775538e-03, 4.85004010e-04], [7.20506572e-01, 5.99391592e-03, 4.16868776e-04], [8.08597385e-01, 7.03285951e-03, 4.86558499e-04], ..., ... [1.01084365e+01, 6.41838820e-04, 4.51900087e-05], [1.19558543e+01, 6.33722789e-04, 4.46634907e-05], [1.52506997e+01, 8.34603216e-04, 5.95718011e-05]], [[1.14401990e+01, 5.13848524e-04, 3.66806790e-05], [2.43402332e+01, 5.07572362e-04, 3.61362807e-05], [2.35010568e+01, 7.48296871e-04, 5.24890054e-05], ..., [1.12479240e+01, 5.91278873e-04, 4.17588802e-05], [2.55925690e+01, 5.82144726e-04, 4.11840150e-05], [1.45409485e+01, 7.45068802e-04, 5.36403200e-05]], [[1.53069747e+01, 4.61783891e-04, 3.32088235e-05], [1.45487959e+01, 4.55158558e-04, 3.27023914e-05], [1.63691083e+01, 6.95809800e-04, 4.89778851e-05], ..., [1.24804341e+01, 5.46039669e-04, 3.87041672e-05], [1.43373262e+01, 5.38638853e-04, 3.82815835e-05], [1.59937634e+01, 6.60741127e-04, 4.77785040e-05]]], shape=(24, 81, 3)) - seed_turnover_cnp(time_index, cell_id, pft, element)float640.001099 8.793e-05 ... 3.966e-08
- unit :
- kg C
- description :
- Biomasses of plant seed tissue turnover
array([[[[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[8.79805168e-04, 7.03844135e-05, 7.01039975e-06], [8.55900164e-04, 6.84720131e-05, 6.81992162e-06]], [[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55900164e-04, 6.84720131e-05, 6.81992162e-06]], ..., [[1.09918374e-03, 8.79346990e-05, 8.75843616e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[1.09929283e-03, 8.79434262e-05, 8.75930540e-06], [8.55410720e-04, 6.84328576e-05, 6.81602167e-06]], [[1.09940192e-03, 8.79521534e-05, 8.76017464e-06], [8.55737016e-04, 6.84589613e-05, 6.81862164e-06]]], ... [[[2.31865062e-02, 5.78200344e-06, 5.79813539e-07], [3.40502204e-02, 5.28523932e-07, 7.94478832e-08]], [[2.98315770e-02, 5.73432552e-06, 5.77628469e-07], [3.47208474e-02, 4.68024094e-07, 6.82507426e-08]], [[2.97063234e-02, 9.22051799e-06, 9.29664980e-07], [4.48516107e-02, 3.39641717e-08, 5.37900117e-09]], ..., [[2.48964426e-02, 7.21469416e-06, 7.31647635e-07], [3.08257744e-02, 5.83727350e-08, 8.76359180e-09]], [[2.40538370e-02, 7.10377173e-06, 7.22633369e-07], [4.22323707e-02, 7.72873545e-08, 1.02067871e-08]], [[3.49423887e-02, 8.68471419e-06, 8.83958075e-07], [3.49473092e-02, 1.38889726e-07, 3.96588789e-08]]]], shape=(24, 81, 2, 3)) - seed_turnover_cnp_consumed(time_index, cell_id, pft, element)float641.134e-08 9.074e-10 ... 0.0 0.0
- unit :
- kg
- description :
- C, N, and P of seed turnover consumed by animals
array([[[[1.13423746e-08, 9.07389964e-10, 9.03774865e-11], [6.86930469e-09, 5.49544375e-10, 5.47354955e-11]], [[7.26668643e-09, 5.81334914e-10, 5.79018839e-11], [6.87716781e-09, 5.50173425e-10, 5.47981499e-11]], [[1.13423746e-08, 9.07389964e-10, 9.03774865e-11], [6.87716781e-09, 5.50173425e-10, 5.47981499e-11]], ..., [[1.13423746e-08, 9.07389964e-10, 9.03774865e-11], [6.86930469e-09, 5.49544375e-10, 5.47354955e-11]], [[1.13446260e-08, 9.07570084e-10, 9.03954267e-11], [6.86930469e-09, 5.49544375e-10, 5.47354955e-11]], [[1.13468778e-08, 9.07750221e-10, 9.04133687e-11], [6.87454627e-09, 5.49963702e-10, 5.47772611e-11]]], ... [[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], ..., [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]]], shape=(24, 81, 2, 3)) - senesced_leaf_lignin(time_index, cell_id)float640.05 0.05 0.05 ... 0.05 0.05 0.05
- units :
- m
- description :
- Proportion of carbon in leaf turnover that is lignin carbon
- unit :
- unitless
array([[0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05], [0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05], [0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05], ..., [0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05], [0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05], [0.05, 0.05, 0.05, ..., 0.05, 0.05, 0.05]], shape=(24, 81)) - shortwave_absorption(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- W m-2
- description :
- Shortwave radiation absorbed by individual canopy layers
array([[[ nan, nan, nan, ..., nan, nan, nan], [2.79261418e+00, 2.42619067e+00, 2.79315999e+00, ..., 2.79261418e+00, 2.79279666e+00, 2.79334302e+00], [ nan, nan, nan, ..., nan, nan, nan], ..., [7.89160371e+02, 7.89302314e+02, 7.89160159e+02, ..., 7.89160371e+02, 7.89160300e+02, 7.89160089e+02], [1.24804701e+03, 1.24827150e+03, 1.24804668e+03, ..., 1.24804701e+03, 1.24804690e+03, 1.24804657e+03], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [3.81137369e+00, 3.35648253e+00, 3.83438596e+00, ..., 3.80879226e+00, 3.34620919e+00, 3.81296298e+00], [ nan, nan, nan, ..., nan, nan, nan], ... 1.97155292e+03, 1.96121582e+03, 1.95174689e+03], [1.49603846e-65, 1.34856747e-65, 2.21002498e-65, ..., 9.35612558e-66, 1.52549075e-65, 1.14024698e-65], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [7.67576978e+01, 8.86212242e+01, 9.96749646e+01, ..., 7.59031339e+01, 8.70699561e+01, 9.70999361e+01], [ nan, nan, nan, ..., nan, nan, nan], ..., [1.96324230e+03, 1.95137878e+03, 1.94032504e+03, ..., 1.96409687e+03, 1.95293004e+03, 1.94290006e+03], [4.29792688e-67, 4.35295161e-67, 8.11365281e-67, ..., 2.91544372e-67, 5.30766883e-67, 3.82657481e-67], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - soil_c_pool_arbuscular_mycorrhiza(time_index, cell_id)float640.001427 0.001844 ... 0.0005176
- unit :
- kg{C} m^-3
- description :
- Soil arbuscular mycorrhizal fungal biomass (carbon) pool
array([[0.00142685, 0.00184401, 0.00226093, ..., 0.00142724, 0.00142756, 0.00142675], [0.00135152, 0.00174538, 0.00213768, ..., 0.00135149, 0.00134883, 0.00135059], [0.00127296, 0.00164331, 0.00201329, ..., 0.00127193, 0.00127143, 0.00127235], ..., [0.00052851, 0.0006779 , 0.00082589, ..., 0.00053013, 0.00053766, 0.00054091], [0.00051518, 0.00065978, 0.000804 , ..., 0.00051695, 0.00052553, 0.0005292 ], [0.00050125, 0.00064064, 0.00077945, ..., 0.00050327, 0.00051216, 0.00051757]], shape=(24, 81)) - soil_c_pool_bacteria(time_index, cell_id)float640.00128 0.001717 ... 0.01524
- unit :
- kg{C} m^-3
- description :
- Soil bacterial biomass (carbon) pool
array([[0.00127992, 0.00171718, 0.00215384, ..., 0.00129107, 0.00128902, 0.00129525], [0.00116512, 0.00167076, 0.00221023, ..., 0.00119804, 0.0011786 , 0.00121791], [0.00116359, 0.00176681, 0.00253475, ..., 0.0012173 , 0.00115627, 0.00127271], ..., [0.00936717, 0.22566611, 0.78856722, ..., 0.00709626, 0.00736458, 0.01286813], [0.01004879, 0.26466446, 0.84306428, ..., 0.00752798, 0.00780321, 0.01397007], [0.01085181, 0.3156362 , 0.83677668, ..., 0.00801558, 0.00832163, 0.01524078]], shape=(24, 81)) - soil_c_pool_ectomycorrhiza(time_index, cell_id)float640.001427 0.001844 ... 0.0004714
- unit :
- kg{C} m^-3
- description :
- Soil ectomycorrhizal fungal biomass (carbon) pool
array([[0.00142666, 0.00184385, 0.00226074, ..., 0.00142705, 0.00142737, 0.00142657], [0.00135112, 0.00174503, 0.00213728, ..., 0.00135109, 0.00134847, 0.0013502 ], [0.00127233, 0.00164278, 0.00201268, ..., 0.00127136, 0.00127088, 0.00127173], ..., [0.00050086, 0.00064654, 0.00078981, ..., 0.00050283, 0.00050583, 0.00050602], [0.00048318, 0.00062343, 0.00076212, ..., 0.0004853 , 0.00048872, 0.0004888 ], [0.00046486, 0.00059924, 0.00073197, ..., 0.00046721, 0.00047044, 0.00047144]], shape=(24, 81)) - soil_c_pool_saprotrophic_fungi(time_index, cell_id)float640.001426 0.001958 ... 0.005834
- unit :
- kg{C} m^-3
- description :
- Soil saprotrophic fungal biomass (carbon) pool
array([[0.00142584, 0.00195793, 0.00246997, ..., 0.00142516, 0.00143085, 0.00143302], [0.00142234, 0.00214288, 0.00281713, ..., 0.00142152, 0.00143597, 0.00143605], [0.00146642, 0.00245638, 0.00334269, ..., 0.00146679, 0.00149135, 0.001486 ], ..., [0.0047172 , 0.0281992 , 0.05723133, ..., 0.00406924, 0.00431499, 0.00529757], [0.00491667, 0.03060747, 0.0595434 , ..., 0.00421931, 0.00447131, 0.00555169], [0.00514393, 0.03350314, 0.05995825, ..., 0.00438532, 0.0046515 , 0.00583407]], shape=(24, 81)) - soil_cnp_pool_lmwc(time_index, cell_id, element)float640.2989 0.03299 ... 0.2338 0.178
- unit :
- kg m^-3
- description :
- Soil low molecular weight organic pool. Carbon, nitrogen and phosphorous content
array([[[0.29887711, 0.03298836, 0.00630596], [1.05533644, 0.12848929, 0.01504781], [1.61885786, 0.21802215, 0.02265603], ..., [0.29776269, 0.03442913, 0.00744643], [0.30604287, 0.03447841, 0.0066174 ], [0.31682133, 0.03562867, 0.00715876]], [[0.58117787, 0.06256553, 0.01098599], [1.82462383, 0.22156217, 0.02615514], [2.54139354, 0.34650229, 0.03822376], ..., [0.58047424, 0.06411327, 0.01229554], [0.60532935, 0.0646608 , 0.01054324], [0.61495772, 0.0712836 , 0.01448577]], [[0.81058208, 0.09076541, 0.02123081], [2.42771007, 0.28570972, 0.03999175], [3.19153772, 0.42690684, 0.06027043], ..., ... ..., [0.71088897, 0.08895476, 0.03246236], [0.72779957, 0.08896236, 0.03101161], [0.93805861, 0.25194548, 0.1922847 ]], [[0.77016775, 0.146411 , 0.09188853], [1.47064736, 0.19085364, 0.06949015], [0.35732602, 0.0418353 , 0.01255841], ..., [0.68857695, 0.08609526, 0.03136343], [0.70492989, 0.08610527, 0.02996344], [0.90702285, 0.24289614, 0.18514013]], [[0.74461336, 0.14120924, 0.08845781], [1.28175256, 0.16401177, 0.05895149], [0.17237062, 0.01910675, 0.00540471], ..., [0.66650229, 0.08325728, 0.03026896], [0.6821473 , 0.08324961, 0.02891348], [0.87604769, 0.2338117 , 0.17795442]]], shape=(24, 81, 3)) - soil_cnp_pool_maom(time_index, cell_id, element)float640.9919 0.1976 ... 0.4065 0.1685
- unit :
- kg m^-3
- description :
- Soil mineral associated organic matter pool. Carbon, nitrogen and phosphorous content
array([[[0.99193569, 0.19756656, 0.00854117], [1.10278808, 0.21653557, 0.01238095], [1.13017543, 0.21969351, 0.01496593], ..., [0.99270433, 0.19774488, 0.008565 ], [0.99044236, 0.19726923, 0.00853246], [0.98917443, 0.19700276, 0.0085289 ]], [[0.99721261, 0.19718838, 0.00901478], [1.05781984, 0.20338503, 0.01369045], [1.00953197, 0.19099952, 0.01619439], ..., [0.99784153, 0.19738881, 0.00907462], [0.99458312, 0.19662844, 0.00899048], [0.99481032, 0.19671341, 0.00906512]], [[1.01338147, 0.19841224, 0.00960076], [1.0718713 , 0.20098302, 0.01483962], [1.00430637, 0.18478341, 0.01749753], ..., ... ..., [1.55325545, 0.26643738, 0.03524683], [1.56451678, 0.26573097, 0.0339437 ], [1.73040388, 0.39115858, 0.15705123]], [[1.64451797, 0.31913915, 0.08612375], [2.79747772, 0.44366288, 0.10731084], [3.25522947, 0.5358554 , 0.13963465], ..., [1.57523149, 0.2692301 , 0.036271 ], [1.58703197, 0.26853083, 0.03492682], [1.75995889, 0.39893754, 0.16285747]], [[1.66879622, 0.3237357 , 0.08893787], [2.87913999, 0.45673463, 0.11175114], [3.3802437 , 0.55933841, 0.14722153], ..., [1.59667648, 0.27196338, 0.03727013], [1.60903946, 0.27127885, 0.03588874], [1.7888407 , 0.40649039, 0.16845986]]], shape=(24, 81, 3)) - soil_cnp_pool_necromass(time_index, cell_id, element)float640.0005323 9.164e-05 ... 6.603e-06
- unit :
- kg m^-3
- description :
- Necrotic organic matter pool. Carbon, nitrogen and phosphorous content
array([[[5.32314607e-04, 9.16355689e-05, 2.32062596e-05], [3.68266237e-03, 6.36752907e-04, 1.61013165e-04], [6.83301931e-03, 1.18187079e-03, 2.98821148e-04], ..., [5.32292400e-04, 9.16358242e-05, 2.32072186e-05], [5.32211526e-04, 9.16232913e-05, 2.32034047e-05], [5.32472309e-04, 9.16639490e-05, 2.32147374e-05]], [[2.64559793e-04, 4.53169315e-05, 1.14859280e-05], [1.78476932e-03, 3.08309187e-04, 7.79768946e-05], [3.30515656e-03, 5.71340713e-04, 1.44483725e-04], ..., [2.64677610e-04, 4.53460682e-05, 1.14965836e-05], [2.64286129e-04, 4.52822556e-05, 1.14767383e-05], [2.64990546e-04, 4.53993541e-05, 1.15117641e-05]], [[1.39475262e-04, 2.36191570e-05, 6.00872214e-06], [8.79293131e-04, 1.51518919e-04, 3.83545007e-05], [1.61991988e-03, 2.79598686e-04, 7.07703148e-05], ..., ... [5.44302119e-05, 9.88276183e-06, 2.94978075e-06], [5.53525087e-05, 1.00492636e-05, 2.99523666e-06], [9.33932285e-05, 1.72503534e-05, 5.26560951e-06]], [[7.56950141e-05, 1.38876361e-05, 4.19457466e-06], [1.70541221e-03, 3.24792171e-04, 1.03644368e-04], [5.22413047e-03, 9.98797402e-04, 3.20988323e-04], ..., [5.77740992e-05, 1.05136419e-05, 3.14423599e-06], [5.95542314e-05, 1.08354143e-05, 3.23577588e-06], [1.01778465e-04, 1.88370380e-05, 5.76239455e-06]], [[8.73203661e-05, 1.60561871e-05, 4.86056104e-06], [2.19879907e-03, 4.19114372e-04, 1.33942477e-04], [5.80138771e-03, 1.10910253e-03, 3.56392723e-04], ..., [6.53831789e-05, 1.19252157e-05, 3.57357767e-06], [6.93724706e-05, 1.26503038e-05, 3.78563220e-06], [1.16145301e-04, 2.15386470e-05, 6.60337220e-06]]], shape=(24, 81, 3)) - soil_cnp_pool_pom(time_index, cell_id, element)float640.7738 0.06958 ... 0.5389 0.05393
- unit :
- kg m^-3
- description :
- Particulate organic matter pool. Carbon, nitrogen and phosphorous content
array([[[7.73832248e-01, 6.95835134e-02, 6.93462562e-03], [2.81399976e-01, 3.29696048e-02, 3.29745632e-03], [1.34275278e-01, 2.00998657e-02, 2.01242892e-03], ..., [7.72122742e-01, 6.92108241e-02, 6.89704616e-03], [7.50872688e-01, 6.80018977e-02, 6.77686973e-03], [7.75094509e-01, 7.03460998e-02, 7.01206096e-03]], [[1.54941424e+00, 1.29416457e-01, 1.29312455e-02], [5.23904910e-01, 4.76974261e-02, 4.77518247e-03], [2.56447324e-01, 2.60806765e-02, 2.61165632e-03], ..., [1.54460745e+00, 1.29126571e-01, 1.29020154e-02], [1.61634255e+00, 1.34370296e-01, 1.34282066e-02], [1.56575668e+00, 1.30628207e-01, 1.30536065e-02]], [[2.47727030e+00, 1.89893019e-01, 1.89895665e-02], [9.12710852e-01, 6.51488540e-02, 6.52316804e-03], [4.35830424e-01, 3.01646841e-02, 3.02059036e-03], ..., ... [8.16383302e+00, 5.33839541e-01, 5.34236670e-02], [8.12021252e+00, 5.30723729e-01, 5.31110203e-02], [8.12924492e+00, 5.31216543e-01, 5.31626623e-02]], [[8.24443339e+00, 5.38082244e-01, 5.38494845e-02], [5.80291455e+00, 3.12574462e-01, 3.12912759e-02], [4.10530020e+00, 1.92401788e-01, 1.92567428e-02], ..., [8.21638201e+00, 5.36886510e-01, 5.37280136e-02], [8.16976856e+00, 5.33569323e-01, 5.33950136e-02], [8.18751706e+00, 5.34638619e-01, 5.35041257e-02]], [[8.31902107e+00, 5.42379018e-01, 5.42787082e-02], [5.87553427e+00, 3.16094007e-01, 3.16425103e-02], [4.15505381e+00, 1.94538531e-01, 1.94692966e-02], ..., [8.28715994e+00, 5.40991341e-01, 5.41379112e-02], [8.24904856e+00, 5.38086863e-01, 5.38456845e-02], [8.25953778e+00, 5.38866012e-01, 5.39257194e-02]]], shape=(24, 81, 3)) - soil_enzyme_maom_bacteria(time_index, cell_id)float640.004817 0.03432 ... 2.469e-05
- unit :
- kg{C} m^-3
- description :
- Amount of bacterial enzyme class which breaks down mineral associated organic matter
array([[4.81694541e-03, 3.43194392e-02, 6.38219345e-02, ..., 4.81698632e-03, 4.81697292e-03, 4.81701127e-03], [2.32074908e-03, 1.65318016e-02, 3.07430202e-02, ..., 2.32086940e-03, 2.32082979e-03, 2.32095943e-03], [1.11888059e-03, 7.96473924e-03, 1.48112502e-02, ..., 1.11906305e-03, 1.11882898e-03, 1.11924369e-03], ..., [1.44593151e-05, 4.22227106e-04, 1.41441917e-03, ..., 1.07387689e-05, 1.09748274e-05, 2.08118211e-05], [1.53400677e-05, 4.93110302e-04, 1.35394747e-03, ..., 1.11320312e-05, 1.13961844e-05, 2.21900598e-05], [1.71610497e-05, 6.13488992e-04, 1.17899983e-03, ..., 1.21485059e-05, 1.26815753e-05, 2.46894567e-05]], shape=(24, 81)) - soil_enzyme_maom_fungi(time_index, cell_id)float640.004817 0.03432 ... 4.6e-06
- unit :
- kg{C} m^-3
- description :
- Amount of fungal enzyme class which breaks down mineral associated organic matter
array([[4.81686864e-03, 3.43195396e-02, 6.38221348e-02, ..., 4.81686333e-03, 4.81688416e-03, 4.81689824e-03], [2.32058893e-03, 1.65319720e-02, 3.07432255e-02, ..., 2.32058819e-03, 2.32065207e-03, 2.32063547e-03], [1.11843299e-03, 7.96488123e-03, 1.48110274e-02, ..., 1.11844275e-03, 1.11850326e-03, 1.11848084e-03], ..., [3.52651150e-06, 2.68205365e-05, 5.17417126e-05, ..., 2.96820390e-06, 3.10565966e-06, 4.19106982e-06], [3.62388731e-06, 2.87189940e-05, 4.67986935e-05, ..., 3.00170114e-06, 3.14693458e-06, 4.29963675e-06], [3.92174396e-06, 3.27084884e-05, 3.95807926e-05, ..., 3.19235486e-06, 3.40939145e-06, 4.60030489e-06]], shape=(24, 81)) - soil_enzyme_pom_bacteria(time_index, cell_id)float640.004817 0.03432 ... 2.469e-05
- unit :
- kg{C} m^-3
- description :
- Amount of bacterial enzyme class which breaks down particulate organic matter
array([[4.81694541e-03, 3.43194392e-02, 6.38219345e-02, ..., 4.81698632e-03, 4.81697292e-03, 4.81701127e-03], [2.32074908e-03, 1.65318016e-02, 3.07430202e-02, ..., 2.32086940e-03, 2.32082979e-03, 2.32095943e-03], [1.11888059e-03, 7.96473924e-03, 1.48112502e-02, ..., 1.11906305e-03, 1.11882898e-03, 1.11924369e-03], ..., [1.44593151e-05, 4.22227106e-04, 1.41441917e-03, ..., 1.07387689e-05, 1.09748274e-05, 2.08118211e-05], [1.53400677e-05, 4.93110302e-04, 1.35394747e-03, ..., 1.11320312e-05, 1.13961844e-05, 2.21900598e-05], [1.71610497e-05, 6.13488992e-04, 1.17899983e-03, ..., 1.21485059e-05, 1.26815753e-05, 2.46894567e-05]], shape=(24, 81)) - soil_enzyme_pom_fungi(time_index, cell_id)float640.004817 0.03432 ... 4.6e-06
- unit :
- kg{C} m^-3
- description :
- Amount of fungal enzyme class which breaks down particulate organic matter
array([[4.81686864e-03, 3.43195396e-02, 6.38221348e-02, ..., 4.81686333e-03, 4.81688416e-03, 4.81689824e-03], [2.32058893e-03, 1.65319720e-02, 3.07432255e-02, ..., 2.32058819e-03, 2.32065207e-03, 2.32063547e-03], [1.11843299e-03, 7.96488123e-03, 1.48110274e-02, ..., 1.11844275e-03, 1.11850326e-03, 1.11848084e-03], ..., [3.52651150e-06, 2.68205365e-05, 5.17417126e-05, ..., 2.96820390e-06, 3.10565966e-06, 4.19106982e-06], [3.62388731e-06, 2.87189940e-05, 4.67986935e-05, ..., 3.00170114e-06, 3.14693458e-06, 4.29963675e-06], [3.92174396e-06, 3.27084884e-05, 3.95807926e-05, ..., 3.19235486e-06, 3.40939145e-06, 4.60030489e-06]], shape=(24, 81)) - soil_evaporation(time_index, cell_id)float6452.06 38.57 ... 3.055e-102
- unit :
- mm
- description :
- Soil evaporation
array([[5.20637119e+001, 3.85697356e+001, 3.69594251e+001, ..., 5.28759663e+001, 3.39432338e+001, 2.72842804e+001], [2.11588778e-003, 3.15565399e-003, 7.63185559e-003, ..., 5.29820139e-003, 8.02747553e-003, 6.69084832e-003], [2.69991082e-012, 3.23449390e-012, 6.05446602e-012, ..., 2.76115118e-012, 7.21651756e-012, 4.81181237e-012], ..., [9.35394434e-098, 2.38238966e-098, 2.06351038e-097, ..., 8.29780299e-098, 1.04117911e-097, 3.47376832e-098], [1.53832279e-100, 2.64656295e-100, 4.52932468e-100, ..., 4.69630388e-100, 7.15330775e-100, 5.56681527e-100], [1.91603381e-102, 2.72143310e-102, 1.35258445e-101, ..., 4.34896227e-102, 7.78366923e-103, 3.05539836e-102]], shape=(24, 81)) - soil_moisture(time_index, layers, cell_id)float64nan nan nan ... 373.7 374.0 373.8
- unit :
- mm
- description :
- Soil moisture
array([[[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [106.56496628, 112.94363081, 111.80357237, ..., 104.56230542, 112.46725688, 115.57734159], [374.62575981, 374.80171872, 374.77800969, ..., 374.58473557, 374.80263302, 374.8575125 ]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ... [ nan, nan, nan, ..., nan, nan, nan], [125.98056539, 126.05520511, 125.70413274, ..., 125.97908959, 125.75507035, 125.79585102], [373.81512899, 374.09986621, 373.87220619, ..., 373.76481643, 374.11610579, 373.91803934]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [126.06094657, 126.13588179, 125.70037296, ..., 125.97533134, 125.7513067 , 125.79209054], [373.74339152, 374.01794317, 373.78309974, ..., 373.68941481, 374.03598943, 373.82706336]]], shape=(24, 14, 81)) - soil_n_pool_ammonium(time_index, cell_id)float640.001024 0.00147 ... 0.01715
- unit :
- kg{N} m^-3
- description :
- Amount of nitrogen contained in the soil ammonium (NH4+) pool
array([[0.00102416, 0.00147014, 0.00175061, ..., 0.00099496, 0.00114484, 0.00123144], [0.00131544, 0.00183292, 0.00197319, ..., 0.00131395, 0.00168126, 0.00151318], [0.00190583, 0.00256292, 0.00246329, ..., 0.00198081, 0.00230374, 0.00197273], ..., [0.01192623, 0.03355783, 0.0942565 , ..., 0.00833596, 0.00849284, 0.01512211], [0.0123624 , 0.03628591, 0.09547512, ..., 0.00854058, 0.00865342, 0.016085 ], [0.01287472, 0.04052437, 0.09449228, ..., 0.00877076, 0.00883026, 0.01714556]], shape=(24, 81)) - soil_n_pool_nitrate(time_index, cell_id)float640.0002019 0.0001793 ... 0.000173
- unit :
- kg{N} m^-3
- description :
- Amount of nitrogen contained in the soil nitrate (NO3-) pool
array([[2.01867189e-04, 1.79263721e-04, 2.41083400e-04, ..., 2.24105385e-04, 1.40343335e-04, 1.14230423e-04], [1.31251306e-04, 1.23719491e-04, 1.67833118e-04, ..., 1.29564884e-04, 1.05003586e-04, 1.31000975e-04], [1.27646149e-04, 1.19567732e-04, 1.68055751e-04, ..., 1.25306348e-04, 1.08628973e-04, 1.43699249e-04], ..., [7.97251028e-05, 2.51598639e-04, 7.92974850e-04, ..., 5.30933149e-05, 5.81406679e-05, 1.33999951e-04], [9.07278186e-05, 3.08418285e-04, 7.73246547e-04, ..., 5.56048389e-05, 6.29584267e-05, 1.45848794e-04], [1.06230115e-04, 3.96277312e-04, 9.63580284e-04, ..., 6.82022260e-05, 8.23689389e-05, 1.72966148e-04]], shape=(24, 81)) - soil_p_pool_labile(time_index, cell_id)float643.73e-05 5.198e-05 ... 0.0131
- unit :
- kg{P} m^-3
- description :
- Amount of inorganic phosphorus that is in a labile form
array([[3.73028349e-05, 5.19770907e-05, 6.71628698e-05, ..., 3.76775581e-05, 3.74239851e-05, 3.76484497e-05], [5.04757066e-05, 7.70790825e-05, 1.06197689e-04, ..., 5.17019840e-05, 5.08569681e-05, 5.21508862e-05], [6.65577223e-05, 1.05258038e-04, 1.52183640e-04, ..., 6.85636768e-05, 6.58100686e-05, 9.13934533e-05], ..., [4.88785070e-03, 1.61899081e-02, 4.12630939e-02, ..., 9.93228826e-04, 8.99483330e-04, 1.14990862e-02], [5.12138046e-03, 1.75152570e-02, 4.00247480e-02, ..., 1.01405399e-03, 9.14275105e-04, 1.22039133e-02], [5.44809737e-03, 1.96512135e-02, 3.83985855e-02, ..., 1.04924174e-03, 9.47563979e-04, 1.31039842e-02]], shape=(24, 81)) - soil_p_pool_primary(time_index, cell_id)float640.001 0.0015 ... 0.0009998
- unit :
- kg{P} m^-3
- description :
- Amount of phosphorus in a primary mineral form
array([[0.00099999, 0.00149999, 0.00199999, ..., 0.00099999, 0.00099999, 0.00099999], [0.00099999, 0.00149998, 0.00199997, ..., 0.00099999, 0.00099999, 0.00099999], [0.00099998, 0.00149997, 0.00199996, ..., 0.00099998, 0.00099998, 0.00099998], ..., [0.00099985, 0.00149977, 0.00199969, ..., 0.00099985, 0.00099985, 0.00099985], [0.00099984, 0.00149976, 0.00199968, ..., 0.00099984, 0.00099984, 0.00099984], [0.00099983, 0.00149975, 0.00199967, ..., 0.00099983, 0.00099983, 0.00099983]], shape=(24, 81)) - soil_p_pool_secondary(time_index, cell_id)float640.00499 0.0106 ... 0.005275 0.01024
- unit :
- kg{P} m^-3
- description :
- Amount of inorganic phosphorus that is associated with secondary minerals
array([[0.00499031, 0.0106031 , 0.0162159 , ..., 0.00499032, 0.00499032, 0.00499032], [0.0049813 , 0.01058249, 0.01618377, ..., 0.00498135, 0.00498132, 0.00498135], [0.00497303, 0.01056327, 0.01615383, ..., 0.00497316, 0.00497304, 0.00497357], ..., [0.00673781, 0.01479731, 0.02768106, ..., 0.00524613, 0.00520535, 0.00903673], [0.00697619, 0.01561769, 0.0296837 , ..., 0.00528517, 0.00523958, 0.00961675], [0.00722821, 0.01652409, 0.03160882, ..., 0.00532554, 0.00527495, 0.01023609]], shape=(24, 81)) - soil_temperature(time_index, layers, cell_id)float64nan nan nan ... 22.02 21.22 21.36
- unit :
- C
- description :
- Soil temperature profile
array([[[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [23.40833389, 23.02165238, 22.67931372, ..., 23.08264969, 23.03465506, 23.31049758], [23.8579326 , 23.56634292, 22.92189207, ..., 23.29639025, 23.45819261, 23.49090457]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ... [ nan, nan, nan, ..., nan, nan, nan], [17.90582035, 17.91786542, 16.97389305, ..., 17.59237426, 17.56417776, 17.74165189], [20.97662124, 21.22860502, 20.09999877, ..., 20.86828842, 21.31891036, 20.42310625]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [19.97763042, 20.04292732, 20.44761818, ..., 19.6206969 , 19.79888288, 19.31073437], [21.94381206, 21.77117719, 22.38686651, ..., 22.01943151, 21.21894303, 21.36305332]]], shape=(24, 14, 81)) - stem_lignin(time_index, cell_id)float640.545 0.545 0.545 ... 0.545 0.545
- units :
- m
- description :
- Proportion of stem carbon that is lignin carbon
- unit :
- unitless
array([[0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545], [0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545], [0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545], ..., [0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545], [0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545], [0.545, 0.545, 0.545, ..., 0.545, 0.545, 0.545]], shape=(24, 81)) - stem_turnover_cnp(time_index, cell_id, element)float640.0 0.0 0.0 7.31 ... 0.0 0.0 0.0
- unit :
- kg
- description :
- C, N, and P masses for stem turnover in a given timestep
array([[[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [7.30958392e+00, 1.20421481e-01, 8.53424860e-03], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [3.51946153e-04, 5.79812444e-06, 2.07054864e-07], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [1.03362981e+01, 1.09984271e-01, 7.85820585e-03], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., ... [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.40884047e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.61935881e+01, 0.00000000e+00, 0.00000000e+00], [5.87629608e+01, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [6.60400802e+01, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[8.23472419e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]], shape=(24, 81, 3)) - subcanopy_ammonium_uptake(time_index, cell_id)float644.266e-12 6.604e-12 ... 2.465e-10
- unit :
- kg
- description :
- Uptake of ammonium by subcanopy transpiration
array([[4.26561239e-12, 6.60401412e-12, 8.82607712e-12, ..., 4.27260023e-12, 4.36780974e-12, 4.19668074e-12], [7.97607603e-12, 1.12184182e-11, 1.23869721e-11, ..., 7.78055145e-12, 7.72920533e-12, 9.27208657e-12], [6.87042228e-12, 9.25648860e-12, 1.02974484e-11, ..., 6.53186238e-12, 9.17817100e-12, 8.12483553e-12], ..., [2.28528604e-10, 6.44682135e-10, 1.78367534e-09, ..., 1.52487833e-10, 1.63265864e-10, 2.60893738e-10], [2.13314673e-10, 6.05630162e-10, 1.75372131e-09, ..., 1.53569365e-10, 1.59843114e-10, 2.64312673e-10], [1.83593005e-10, 5.24854292e-10, 1.35763645e-09, ..., 1.32672646e-10, 1.24446273e-10, 2.46514494e-10]], shape=(24, 81)) - subcanopy_nitrate_uptake(time_index, cell_id)float648.531e-11 1.321e-10 ... 4.47e-11
- unit :
- kg
- description :
- Uptake of nitrate by subcanopy transpiration
array([[8.53122478e-11, 1.32080282e-10, 1.76521542e-10, ..., 8.54520045e-11, 8.73561949e-11, 8.39336148e-11], [3.14425719e-11, 2.73586089e-11, 3.41170827e-11, ..., 3.50497860e-11, 1.89500418e-11, 1.72019056e-11], [1.37102805e-11, 1.24960071e-11, 1.75173182e-11, ..., 1.28817644e-11, 1.14645101e-11, 1.40678897e-11], ..., [3.27592624e-11, 1.06283423e-10, 3.63500073e-10, ..., 1.88988613e-11, 2.32558505e-11, 4.59777519e-11], [2.85195532e-11, 9.08138231e-11, 2.95079268e-10, ..., 1.95622563e-11, 2.18852315e-11, 4.68425276e-11], [2.69478379e-11, 8.92217760e-11, 2.19908107e-10, ..., 1.72757402e-11, 1.81083108e-11, 4.47048090e-11]], shape=(24, 81)) - subcanopy_phosphorus_uptake(time_index, cell_id)float641.066e-14 1.238e-14 ... 1.87e-11
- unit :
- kg
- description :
- Uptake of phosphorous by subcanopy transpiration
array([[1.06640310e-14, 1.23825265e-14, 1.37907455e-14, ..., 1.06815006e-14, 1.09195244e-14, 1.04917019e-14], [2.90512063e-14, 3.96628187e-14, 4.75229980e-14, ..., 2.94636014e-14, 2.52661119e-14, 2.83473116e-14], [2.63630175e-14, 3.89259910e-14, 5.54210850e-14, ..., 2.57019014e-14, 2.77633482e-14, 2.80018113e-14], ..., [9.32767765e-12, 3.12359613e-11, 8.13057428e-11, ..., 1.82744516e-12, 1.74102232e-12, 1.99512683e-11], [8.74249849e-12, 2.92185097e-11, 7.67734533e-11, ..., 1.82977809e-12, 1.69291149e-12, 2.00987484e-11], [7.60572294e-12, 2.53347874e-11, 5.69143607e-11, ..., 1.57527058e-12, 1.31483414e-12, 1.87033981e-11]], shape=(24, 81)) - subcanopy_seedbank_biomass(time_index, cell_id)float640.1654 0.166 0.166 ... 2.44 2.444
- unit :
- kg C m^-2
- description :
- Carbon biomass of subcanopy seedbank.
array([[0.1653725 , 0.16604227, 0.16603787, ..., 0.16546696, 0.1658353 , 0.16509869], [0.39163543, 0.39088929, 0.38532486, ..., 0.39214501, 0.38178837, 0.38913803], [0.5670462 , 0.56371282, 0.56126691, ..., 0.56345521, 0.56179476, 0.5669549 ], ..., [2.3515682 , 2.35290326, 2.34540329, ..., 2.35851264, 2.35090352, 2.35505866], [2.40040389, 2.39988455, 2.3903619 , ..., 2.40604235, 2.39671787, 2.40144014], [2.44521241, 2.44294118, 2.4326692 , ..., 2.45071397, 2.44020091, 2.44367713]], shape=(24, 81)) - subcanopy_seedbank_cnp(time_index, cell_id, element)float640.1654 0.003483 ... 0.0002089
- unit :
- kg
- description :
- C, N, and P masses for the subcanopy seedbank CNP
array([[[1.65372499e-01, 3.48316308e-03, 1.39326523e-03], [1.66042267e-01, 3.48328021e-03, 1.39331208e-03], [1.66037873e-01, 3.48327945e-03, 1.39331177e-03], ..., [1.65466961e-01, 3.48317969e-03, 1.39327187e-03], [1.65835299e-01, 3.48324417e-03, 1.39329766e-03], [1.65098689e-01, 3.48311478e-03, 1.39324591e-03]], [[3.91635435e-01, 3.36109741e-03, 1.34443896e-03], [3.90889295e-01, 3.36057212e-03, 1.34422884e-03], [3.85324858e-01, 3.35932003e-03, 1.34372800e-03], ..., [3.92145007e-01, 3.36115833e-03, 1.34446333e-03], [3.81788372e-01, 3.35861361e-03, 1.34344544e-03], [3.89138035e-01, 3.36069407e-03, 1.34427762e-03]], [[5.67046198e-01, 3.15310421e-03, 1.26124168e-03], [5.63712818e-01, 3.15206049e-03, 1.26082419e-03], [5.61266912e-01, 3.15259345e-03, 1.26103737e-03], ..., ... [2.35851264e+00, 6.24332273e-04, 2.49732882e-04], [2.35090352e+00, 6.24484816e-04, 2.49793898e-04], [2.35505866e+00, 6.24293328e-04, 2.49717298e-04]], [[2.40040389e+00, 5.71054646e-04, 2.28421825e-04], [2.39988455e+00, 5.71089142e-04, 2.28435600e-04], [2.39036190e+00, 5.71147573e-04, 2.28458907e-04], ..., [2.40604235e+00, 5.71117462e-04, 2.28446956e-04], [2.39671787e+00, 5.71234861e-04, 2.28493914e-04], [2.40144014e+00, 5.71068653e-04, 2.28427425e-04]], [[2.44521241e+00, 5.22331566e-04, 2.08932590e-04], [2.44294118e+00, 5.22343112e-04, 2.08937179e-04], [2.43266920e+00, 5.22389052e-04, 2.08955473e-04], ..., [2.45071397e+00, 5.22385093e-04, 2.08954007e-04], [2.44020091e+00, 5.22478887e-04, 2.08991523e-04], [2.44367713e+00, 5.22314802e-04, 2.08925881e-04]]], shape=(24, 81, 3)) - subcanopy_seedbank_cnp_consumed(time_index, cell_id, element)float640.0002429 5.117e-06 ... 0.0 0.0
- unit :
- kg C m^-2
- description :
- C, N, and P masses of subcanopy seedbank consumed by animals.
array([[[2.42935235e-04, 5.11683047e-06, 2.04673218e-06], [2.44878954e-04, 5.13713783e-06, 2.05485512e-06], [2.44866174e-04, 5.13700458e-06, 2.05480182e-06], ..., [2.43208901e-04, 5.11969460e-06, 2.04787784e-06], [2.44277489e-04, 5.13086263e-06, 2.05234505e-06], [2.42142849e-04, 5.10852835e-06, 2.04341133e-06]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., ... [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]], shape=(24, 81, 3)) - subcanopy_seedbank_litter_cnp(time_index, cell_id, element)float640.006105 0.0003052 ... 1.992e-05
- unit :
- kg
- description :
- C, N, and P masses for the ground seedbank
array([[[6.10485634e-03, 3.05242817e-04, 1.22097127e-04], [6.10485634e-03, 3.05242817e-04, 1.22097127e-04], [6.10485634e-03, 3.05242817e-04, 1.22097127e-04], ..., [6.10485634e-03, 3.05242817e-04, 1.22097127e-04], [6.10485634e-03, 3.05242817e-04, 1.22097127e-04], [6.10485634e-03, 3.05242817e-04, 1.22097127e-04]], [[1.44225050e-02, 3.03774432e-04, 1.21509772e-04], [1.44809170e-02, 3.03784647e-04, 1.21513858e-04], [1.44805337e-02, 3.03784581e-04, 1.21513832e-04], ..., [1.44307432e-02, 3.03775880e-04, 1.21510352e-04], [1.44628668e-02, 3.03781503e-04, 1.21512601e-04], [1.43986255e-02, 3.03770220e-04, 1.21508088e-04]], [[3.41554010e-02, 2.93128812e-04, 1.17251524e-04], [3.40903284e-02, 2.93083001e-04, 1.17233199e-04], [3.36050414e-02, 2.92973803e-04, 1.17189520e-04], ..., ... [2.01089479e-01, 5.95131009e-05, 2.38052381e-05], [2.00722342e-01, 5.95323286e-05, 2.38129291e-05], [2.00961077e-01, 5.95119594e-05, 2.38047811e-05]], [[2.05085515e-01, 5.44415729e-05, 2.17766265e-05], [2.05201949e-01, 5.44471797e-05, 2.17788676e-05], [2.04547859e-01, 5.44550972e-05, 2.17820303e-05], ..., [2.05691155e-01, 5.44494119e-05, 2.17797624e-05], [2.05027547e-01, 5.44627156e-05, 2.17850838e-05], [2.05389926e-01, 5.44460155e-05, 2.17784033e-05]], [[2.09344584e-01, 4.98029511e-05, 1.99211775e-05], [2.09299291e-01, 4.98059596e-05, 1.99223788e-05], [2.08468800e-01, 4.98110555e-05, 1.99244115e-05], ..., [2.09836327e-01, 4.98084295e-05, 1.99233693e-05], [2.09023118e-01, 4.98186680e-05, 1.99274646e-05], [2.09434958e-01, 4.98041727e-05, 1.99216659e-05]]], shape=(24, 81, 3)) - subcanopy_seedbank_litter_lignin(time_index, cell_id)int640 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0
- unit :
- unitless
- description :
- Proportion of subcanopy seedbank litter carbon that is lignin carbon
array([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], shape=(24, 81)) - subcanopy_vegetation_biomass(time_index, cell_id)float640.9801 0.9862 ... 23.34 23.37
- unit :
- kg C m^-2
- description :
- Carbon biomass of vegetation growing underneath the canopy.
array([[ 0.98013414, 0.98616206, 0.98612251, ..., 0.9809843 , 0.98429934, 0.97766986], [ 3.07088956, 3.06422294, 3.01414269, ..., 3.07548258, 2.9822996 , 3.04839308], [ 4.71586991, 4.68585989, 4.66344239, ..., 4.68359432, 4.66792276, 4.71484862], ..., [22.40730839, 22.42139015, 22.35005081, ..., 22.47445167, 22.40386211, 22.44475232], [22.9139173 , 22.91123408, 22.82146626, ..., 22.96942386, 22.88301923, 22.92902402], [23.38223343, 23.36357954, 23.26671513, ..., 23.4365204 , 23.33894861, 23.37378955]], shape=(24, 81)) - subcanopy_vegetation_cnp(time_index, cell_id, element)float640.9801 0.00292 ... 0.0001167
- unit :
- kg
- description :
- C, N, and P masses for subcanopy vegetation
array([[[9.80134143e-01, 2.91972775e-03, 1.16789107e-03], [9.86162061e-01, 2.91961067e-03, 1.16784422e-03], [9.86122507e-01, 2.91961148e-03, 1.16784453e-03], ..., [9.80984300e-01, 2.91971115e-03, 1.16788443e-03], [9.84299344e-01, 2.91964667e-03, 1.16785863e-03], [9.77669860e-01, 2.91977605e-03, 1.16791039e-03]], [[3.07088956e+00, 2.49454173e-03, 9.97816651e-04], [3.06422294e+00, 2.49506662e-03, 9.98026590e-04], [3.01414269e+00, 2.49631876e-03, 9.98527430e-04], ..., [3.07548258e+00, 2.49448075e-03, 9.97792258e-04], [2.98229960e+00, 2.49702522e-03, 9.98810049e-04], [3.04839308e+00, 2.49494525e-03, 9.97978062e-04]], [[4.71586991e+00, 2.20138528e-03, 8.80554067e-04], [4.68585989e+00, 2.20243064e-03, 8.80972197e-04], [4.66344239e+00, 2.20190252e-03, 8.80760933e-04], ..., ... [2.24744517e+01, 3.49806672e-04, 1.39922329e-04], [2.24038621e+01, 3.49633957e-04, 1.39853220e-04], [2.24447523e+01, 3.49834171e-04, 1.39933200e-04]], [[2.29139173e+01, 3.19470174e-04, 1.27787596e-04], [2.29112341e+01, 3.19437531e-04, 1.27773917e-04], [2.28214663e+01, 3.19375060e-04, 1.27747067e-04], ..., [2.29694239e+01, 3.19401721e-04, 1.27760314e-04], [2.28830192e+01, 3.19265259e-04, 1.27705704e-04], [2.29290240e+01, 3.19440326e-04, 1.27775602e-04]], [[2.33822334e+01, 2.91749764e-04, 1.16699400e-04], [2.33635795e+01, 2.91740189e-04, 1.16694865e-04], [2.32667151e+01, 2.91691286e-04, 1.16673265e-04], ..., [2.34365204e+01, 2.91690770e-04, 1.16675911e-04], [2.33389486e+01, 2.91579046e-04, 1.16631201e-04], [2.33737896e+01, 2.91752036e-04, 1.16700239e-04]]], shape=(24, 81, 3)) - subcanopy_vegetation_cnp_consumed(time_index, cell_id, element)float640.008843 2.634e-05 ... 2.935e-08
- unit :
- kg C m^-2
- description :
- C, N, and P masses of subcanopy vegetation consumed by animals.
array([[[8.84277935e-03, 2.63418109e-05, 1.05367241e-05], [9.15468071e-03, 2.71031553e-05, 1.08412617e-05], [9.13311557e-03, 2.70404021e-05, 1.08161602e-05], ..., [8.97656337e-03, 2.67170149e-05, 1.06868057e-05], [9.09943439e-03, 2.69909083e-05, 1.07963630e-05], [8.80868311e-03, 2.63068169e-05, 1.05227265e-05]], [[5.26969745e-04, 4.28067500e-07, 1.71226993e-07], [4.99833144e-04, 4.06992903e-07, 1.62797152e-07], [4.83638320e-04, 4.00550185e-07, 1.60220062e-07], ..., [1.40975508e-03, 1.14343256e-06, 4.57373004e-07], [1.08332970e-03, 9.07052251e-07, 3.62820887e-07], [1.03882544e-03, 8.50222571e-07, 3.40089016e-07]], [[2.35585609e-04, 1.09972222e-07, 4.39888865e-08], [9.05838137e-04, 4.25758711e-07, 1.70303473e-07], [1.61244403e-03, 7.61335572e-07, 3.04534202e-07], ..., ... [2.99113174e-03, 4.65558784e-08, 1.86223062e-08], [4.94821668e-03, 7.72217115e-08, 3.08886044e-08], [6.80213708e-03, 1.06021218e-07, 4.24083452e-08]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.87281053e-04, 8.21870599e-09, 3.28740630e-09], ..., [4.49524448e-03, 6.25086999e-08, 2.50034067e-08], [6.09500708e-03, 8.50379048e-08, 3.40150555e-08], [5.96634139e-03, 8.31212893e-08, 3.32483783e-08]], [[0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [2.80372995e-03, 3.50100764e-08, 1.40038853e-08], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [9.41504407e-03, 1.17179573e-07, 4.68716696e-08], [4.92008222e-03, 6.14677594e-08, 2.45870158e-08], [5.87751680e-03, 7.33632640e-08, 2.93451609e-08]]], shape=(24, 81, 3)) - subcanopy_vegetation_litter_cnp(time_index, cell_id, element)float640.005837 0.0002919 ... 1.066e-05
- unit :
- kg
- description :
- C, N, and P masses for subcanopy turnover in a given timestep
array([[[5.83732877e-03, 2.91866438e-04, 1.16746575e-04], [5.83732877e-03, 2.91866438e-04, 1.16746575e-04], [5.83732877e-03, 2.91866438e-04, 1.16746575e-04], ..., [5.83732877e-03, 2.91866438e-04, 1.16746575e-04], [5.83732877e-03, 2.91866438e-04, 1.16746575e-04], [5.83732877e-03, 2.91866438e-04, 1.16746575e-04]], [[8.17337890e-02, 2.43477297e-04, 9.73909161e-05], [8.22364595e-02, 2.43467534e-04, 9.73870094e-05], [8.22331611e-02, 2.43467601e-04, 9.73870349e-05], ..., [8.18046839e-02, 2.43475912e-04, 9.73903622e-05], [8.20811268e-02, 2.43470536e-04, 9.73882115e-05], [8.15282914e-02, 2.43481325e-04, 9.73925272e-05]], [[2.56082743e-01, 2.08020860e-04, 8.32083405e-05], [2.55526810e-01, 2.08064631e-04, 8.32258475e-05], [2.51350597e-01, 2.08169047e-04, 8.32676127e-05], ..., ... [1.82878806e+00, 3.19563996e-05, 1.27825347e-05], [1.82546469e+00, 3.19362545e-05, 1.27744750e-05], [1.82781894e+00, 3.19564328e-05, 1.27825394e-05]], [[1.86855466e+00, 2.91784928e-05, 1.16713615e-05], [1.86972894e+00, 2.91732814e-05, 1.16692345e-05], [1.86377992e+00, 2.91652518e-05, 1.16658963e-05], ..., [1.87415376e+00, 2.91705221e-05, 1.16681805e-05], [1.86826727e+00, 2.91561193e-05, 1.16624175e-05], [1.87167712e+00, 2.91728153e-05, 1.16690870e-05]], [[1.91080098e+00, 2.66407491e-05, 1.06562601e-05], [1.91057723e+00, 2.66380270e-05, 1.06551195e-05], [1.90309145e+00, 2.66328175e-05, 1.06528804e-05], ..., [1.91542970e+00, 2.66350408e-05, 1.06539851e-05], [1.90822438e+00, 2.66236611e-05, 1.06494311e-05], [1.91206074e+00, 2.66382601e-05, 1.06552600e-05]]], shape=(24, 81, 3)) - subcanopy_vegetation_litter_lignin(time_index, cell_id)int640 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0
- unit :
- unitless
- description :
- Proportion of subcanopy vegetation litter carbon that is lignin carbon.
array([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], shape=(24, 81)) - subsurface_flow(time_index, cell_id)float64669.2 719.5 ... 0.00075 0.00075
- unit :
- mm
- description :
- Subsurface flow
array([[6.69204791e+02, 7.19493877e+02, 6.92016881e+02, ..., 6.81073967e+02, 6.96510859e+02, 6.90272571e+02], [7.43915616e+02, 8.22124048e+02, 7.35136024e+02, ..., 7.92729042e+02, 7.78711174e+02, 6.94120506e+02], [7.68282146e+02, 8.58863784e+02, 7.16920799e+02, ..., 8.45903988e+02, 7.85817422e+02, 6.46273477e+02], ..., [7.50000000e-04, 7.50000000e-04, 7.50000000e-04, ..., 7.50000000e-04, 7.50000000e-04, 7.50000000e-04], [7.50000000e-04, 7.50000000e-04, 7.50000000e-04, ..., 7.50000000e-04, 7.50000000e-04, 7.50000000e-04], [6.27744485e-01, 8.68921386e-01, 7.50000000e-04, ..., 7.50000000e-04, 7.50000000e-04, 7.50000000e-04]], shape=(24, 81)) - subsurface_runoff_routed_plus_local(time_index, cell_id)float646.999e+03 2.841e+03 ... 8.687e+03
- unit :
- mm
- description :
- Subsurface flow contributing to river discharge in each grid cell
array([[ 6999.01793195, 2840.560758 , 1406.5418813 , ..., 1395.59896746, 4186.39003768, 9803.07982227], [ 7722.91532544, 3139.31007218, 1526.16102421, ..., 1583.75404224, 4603.27005085, 10619.7147018 ], [ 8181.29100654, 3310.83458365, 1584.44579915, ..., 1713.42898789, 4875.85836033, 11098.296376 ], ..., [ 6721.30901652, 2732.70649409, 1352.10644877, ..., 1500.94932575, 3990.12433896, 9317.13751351], [ 6496.42151652, 2642.75149409, 1307.12894877, ..., 1455.97182575, 3855.19183896, 9002.29501351], [ 6304.55104698, 2564.27014181, 1262.15144877, ..., 1410.99432575, 3720.25933896, 8687.45251351]], shape=(24, 81)) - surface_runoff(time_index, cell_id)float64127.4 82.1 114.2 ... 0.0 0.0 0.0
- unit :
- mm
- description :
- Surface runoff generated in each grid cell
array([[127.38501079, 82.10114793, 114.23715302, ..., 51.47035677, 68.85461001, 128.08853031], [258.41995738, 246.29733475, 339.65167214, ..., 314.60982016, 314.19758549, 372.38443493], [536.72958167, 505.41799418, 529.6826371 , ..., 433.39357252, 529.82909923, 508.2588894 ], ..., [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 18.97709159, 22.0741803 , 0. , ..., 0. , 0. , 0. ]], shape=(24, 81)) - surface_runoff_routed_plus_local(time_index, cell_id)float64552.2 196.3 114.2 ... 0.0 0.0 0.0
- unit :
- mm
- description :
- Surface runoff contributing to river discharge in each grid cell
array([[ 552.2425732 , 196.33830095, 114.23715302, ..., 51.47035677, 204.01024779, 602.60685941], [1404.81341082, 585.94900689, 339.65167214, ..., 314.60982016, 1002.09983418, 2364.95554271], [2624.53262328, 1035.10063128, 529.6826371 , ..., 433.39357252, 1470.96795505, 3478.92793335], ..., [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 0. , 0. , 0. , ..., 0. , 0. , 0. ], [ 60.02836349, 22.0741803 , 0. , ..., 0. , 0. , 0. ]], shape=(24, 81)) - timestamp(time_index)datetime64[ns]2013-01-01 ... 2014-12-02
array(['2013-01-01T00:00:00.000000000', '2013-01-31T00:00:00.000000000', '2013-03-02T00:00:00.000000000', '2013-04-02T00:00:00.000000000', '2013-05-02T00:00:00.000000000', '2013-06-02T00:00:00.000000000', '2013-07-02T00:00:00.000000000', '2013-08-02T00:00:00.000000000', '2013-09-01T00:00:00.000000000', '2013-10-01T00:00:00.000000000', '2013-11-01T00:00:00.000000000', '2013-12-01T00:00:00.000000000', '2014-01-01T00:00:00.000000000', '2014-01-31T00:00:00.000000000', '2014-03-03T00:00:00.000000000', '2014-04-02T00:00:00.000000000', '2014-05-03T00:00:00.000000000', '2014-06-02T00:00:00.000000000', '2014-07-02T00:00:00.000000000', '2014-08-02T00:00:00.000000000', '2014-09-01T00:00:00.000000000', '2014-10-02T00:00:00.000000000', '2014-11-01T00:00:00.000000000', '2014-12-02T00:00:00.000000000'], dtype='datetime64[ns]') - total_animal_respiration(time_index, cell_id)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- unit :
- ppm
- description :
- Animal respiration aggregated over all functional types
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]], shape=(24, 81)) - total_runoff(time_index, cell_id)float647.551e+03 3.037e+03 ... 8.687e+03
- unit :
- mm
- description :
- Total runoff through each grid cell
array([[ 7551.26050515, 3036.89905895, 1520.77903432, ..., 1447.06932423, 4390.40028547, 10405.68668168], [ 9127.72873626, 3725.25907907, 1865.81269635, ..., 1898.3638624 , 5605.36988502, 12984.67024452], [10805.82362983, 4345.93521493, 2114.12843625, ..., 2146.82256041, 6346.82631538, 14577.22430935], ..., [ 6721.30901652, 2732.70649409, 1352.10644877, ..., 1500.94932575, 3990.12433896, 9317.13751351], [ 6496.42151652, 2642.75149409, 1307.12894877, ..., 1455.97182575, 3855.19183896, 9002.29501351], [ 6364.57941047, 2586.34432211, 1262.15144877, ..., 1410.99432575, 3720.25933896, 8687.45251351]], shape=(24, 81)) - transpiration(time_index, layers, cell_id)float64nan nan nan nan ... nan nan nan nan
- unit :
- mm
- description :
- Transpiration from the canopy and subcanopy
array([[[ nan, nan, nan, ..., nan, nan, nan], [3.63986297e-03, 3.21325927e-03, 3.47543216e-03, ..., 3.71019376e-03, 3.73013300e-03, 3.58836717e-03], [ nan, nan, nan, ..., nan, nan, nan], ..., [8.53122478e-11, 8.80535215e-11, 8.82607712e-11, ..., 8.54520045e-11, 8.73561949e-11, 8.39336148e-11], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [3.12506249e-03, 2.54164364e-03, 3.00649836e-03, ..., 3.38162740e-03, 2.45743273e-03, 3.36783547e-03], [ nan, nan, nan, ..., nan, nan, nan], ... 3.68450460e-10, 3.76418646e-10, 3.49571229e-10], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[ nan, nan, nan, ..., nan, nan, nan], [1.31122315e-01, 1.50844684e-01, 1.64741098e-01, ..., 1.38212649e-01, 1.47348410e-01, 1.68360880e-01], [ nan, nan, nan, ..., nan, nan, nan], ..., [2.97018470e-10, 2.89288218e-10, 2.84395848e-10, ..., 3.10687712e-10, 2.87623305e-10, 3.06514766e-10], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - vapour_pressure(time_index, layers, cell_id)float642.351 2.283 2.354 ... nan nan nan
- unit :
- kPa
- description :
- Vapour pressure profile
array([[[2.35055807, 2.28314896, 2.35430446, ..., 2.31575474, 2.28707109, 2.38533085], [2.35089085, 2.28347162, 2.35462419, ..., 2.31608705, 2.28739732, 2.3856675 ], [ nan, nan, nan, ..., nan, nan, nan], ..., [2.35022744, 2.28282397, 2.35394986, ..., 2.31543524, 2.28675092, 2.38499499], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[3.34727184, 3.43927708, 3.55890469, ..., 3.26901852, 3.69531796, 3.3363309 ], [3.34769797, 3.43965128, 3.55936134, ..., 3.26944511, 3.69578802, 3.33676999], [ nan, nan, nan, ..., nan, nan, nan], ... [1.17567055, 1.12506988, 1.11870387, ..., 1.18001483, 1.09186826, 1.21058558], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[1.6099304 , 1.63596784, 1.69053503, ..., 1.45945881, 1.64934962, 1.54104437], [1.61367762, 1.64037217, 1.69556888, ..., 1.46297707, 1.65370873, 1.54556581], [ nan, nan, nan, ..., nan, nan, nan], ..., [1.60658577, 1.63218115, 1.68580704, ..., 1.45686968, 1.64557128, 1.53685847], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - vapour_pressure_deficit(time_index, layers, cell_id)float640.439 0.4246 0.3515 ... nan nan nan
- unit :
- kPa
- description :
- Vapour pressure deficit profile
array([[[0.43896164, 0.42459318, 0.35149223, ..., 0.46236271, 0.44470394, 0.43756412], [0.43896164, 0.42459318, 0.35149223, ..., 0.46236271, 0.44470394, 0.43756412], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.001 , 0.001 , 0.001 , ..., 0.001 , 0.001 , 0.001 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[0.28065762, 0.23948423, 0.31459818, ..., 0.34376235, 0.29657363, 0.3721686 ], [0.28065762, 0.23948423, 0.31459818, ..., 0.34376235, 0.29657363, 0.3721686 ], [ nan, nan, nan, ..., nan, nan, nan], ... [0.001 , 0.001 , 0.001 , ..., 0.001 , 0.001 , 0.001 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[0.44571947, 0.46495103, 0.43634408, ..., 0.49105261, 0.46351671, 0.42311368], [0.44571947, 0.46495103, 0.43634408, ..., 0.49105261, 0.46351671, 0.42311368], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.001 , 0.001 , 0.001 , ..., 0.001 , 0.001 , 0.001 ], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81)) - vertical_flow(time_index, layers, cell_id)float64nan nan nan ... 0.0005 0.0005
- unit :
- mm per time step (currently day)
- description :
- Vertical flow of water through soil column
array([[[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [0.00312597, 0.00406602, 0.00385357, ..., 0.00282679, 0.00391536, 0.00432853], [0.03286116, 0.02109007, 0.02310143, ..., 0.03751415, 0.02205829, 0.01673028]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ... [ nan, nan, nan, ..., nan, nan, nan], [0.00024257, 0.00024286, 0.00024263, ..., 0.00024252, 0.00024287, 0.00024267], [0.0005 , 0.0005 , 0.0005 , ..., 0.0005 , 0.0005 , 0.0005 ]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [ nan, nan, nan, ..., nan, nan, nan], [0.0002425 , 0.00024277, 0.00024254, ..., 0.00024244, 0.00024279, 0.00024258], [0.0005 , 0.0005 , 0.0005 , ..., 0.0005 , 0.0005 , 0.0005 ]]], shape=(24, 14, 81)) - wind_speed(time_index, layers, cell_id)float640.1885 0.1351 0.1318 ... nan nan
- unit :
- m s-1
- description :
- Wind profile within and below canopy
array([[[0.18852062, 0.13513061, 0.1318014 , ..., 0.19319498, 0.11994811, 0.09124982], [0.18848061, 0.1350906 , 0.13176139, ..., 0.19315496, 0.1199081 , 0.09120981], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.18754879, 0.13415878, 0.13082957, ..., 0.19222314, 0.11897628, 0.09027798], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[0.06968677, 0.10404741, 0.24203092, ..., 0.17270328, 0.23974676, 0.20416301], [0.06964676, 0.10401265, 0.2419909 , ..., 0.17266327, 0.23970675, 0.20412298], [ nan, nan, nan, ..., nan, nan, nan], ... [0.02816132, 0.05667444, 0.04961762, ..., 0.17585467, 0.13642279, 0.14965652], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]], [[0.07501231, 0.09705558, 0.1724549 , ..., 0.24876822, 0.03888232, 0.13428293], [0.07469244, 0.0966877 , 0.17203819, ..., 0.24845325, 0.03852021, 0.13387822], [ nan, nan, nan, ..., nan, nan, nan], ..., [0.05457323, 0.07361134, 0.14590611, ..., 0.22869696, 0.01580134, 0.10845192], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan]]], shape=(24, 14, 81))
This group contains the values of variables as they are updated during the model iteration. All the data in this group has a time dimension, so we can visualise it across time. This can happen in a number of formats such as spatial grids, individual time series within grid cells and as the three dimensional structure of the vertical layers within the simulation. We describe these plotting processes below.
Warning
At present when the Virtual Ecosystem reads in netCDF data it flips it (i.e. the
spatial x dimension becomes the y dimension and vice versa). This doesn’t affect the
simlation, but does need to be corrected for when analysing the spatial outputs, which
will be flipped.
Spatial data#
Using the soil carbon held as mineral-associated organic matter as an example:
# Extract the carbon data
soil_maom_carbon = outputs["soil_cnp_pool_maom"].sel(element="C")
# Make three side by side plots
fig, axes = plt.subplots(ncols=3, figsize=(10, 5))
# Plot start and end MAOM
val_min = soil_maom_carbon.min()
val_max = soil_maom_carbon.max()
# Plot 3 time slices
for idx, ax in zip([0, 10, 23], axes):
im = ax.imshow(
soil_maom_carbon[idx, :].to_numpy().reshape((9, 9)),
extent=extent,
vmax=val_max,
vmin=val_min,
)
ax.set_title(f"Time step: {idx}")
fig.colorbar(im, ax=axes, orientation="vertical", shrink=0.5)
_ = plt.suptitle("Soil carbon: mineral-associated organic matter", y=0.78, x=0.45)
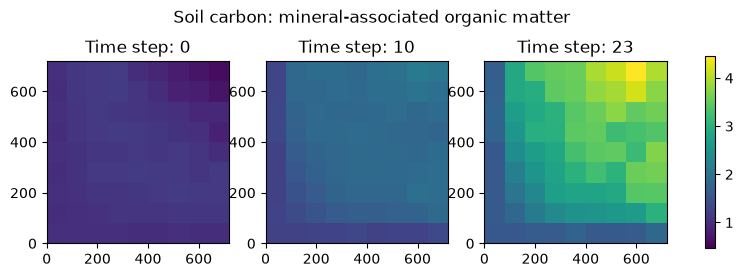
Temporal data#
The plot below shows the mineral-associated organic matter data as a time series showing the values in each cell across time.
plt.plot(outputs["time_index"], soil_maom_carbon)
plt.xlabel("Time step")
_ = plt.ylabel("Soil carbon as MAOM")
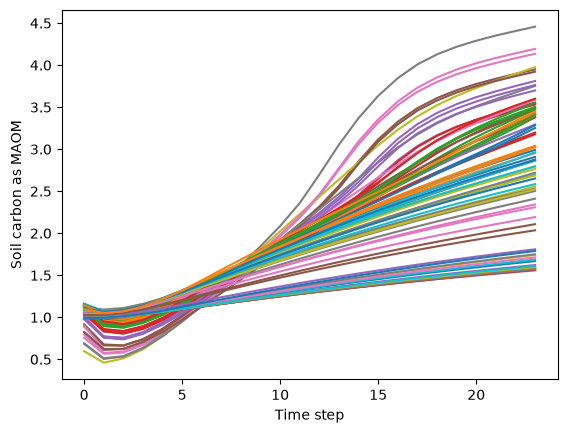
Vertical structure#
The layer heights shown in the initial data example above provide the vertical structure used throughout the simulation. The plot below shows the microclimatic estimates of air temperature through the vertical structure of the canopy.
# Extract the x and y location of the grid cell centres and layer heights
# for all observations at a given time step.
time_index = 0
x_3d = (
outputs["x"]
.broadcast_like(outputs["layer_heights"][time_index])
.to_numpy()
.flatten()
+ 45
)
y_3d = (
outputs["y"]
.broadcast_like(outputs["layer_heights"][time_index])
.to_numpy()
.flatten()
+ 45
)
z_3d = outputs["layer_heights"][time_index].to_numpy().flatten()
# Extract the air temperature for those points to colour the 3D data.
temp_vals = outputs["air_temperature"][time_index].to_numpy().flatten()
# Generate a 3 dimensional plot of layer heights showing temperature.
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(projection="3d")
cmap = plt.get_cmap("turbo")
paths = ax.scatter(x_3d, y_3d, z_3d, c=temp_vals, cmap=cmap)
fig.colorbar(
paths,
ax=ax,
orientation="vertical",
shrink=0.6,
label="Air temperature (°C)",
pad=0.1,
)
ax.set_xlabel("Easting (m)")
ax.set_ylabel("Northing (m)")
ax.set_zlabel("Layer height (m)")
ax.set_xticks(cell_bounds)
_ = ax.set_yticks(cell_bounds)